1 项目概述
| 项目编号 | GDR21060245_std_1 |
| 项目内容 | Mus_musculus --- 3 scRNA-seq |
| 参考基因组 | GRCm39 |
| 样品信息 | NP¦NPM¦PBS |
2 项目流程
2.1 实验流程
 |
| Fig 2-1-1 10x单细胞实验流程图 |
- 细胞质检
取少量单细胞悬液,加入等体积0.4%台盼蓝染液,用 Countess® II Automated Cell Counter 对细胞计数,将活细胞浓度调整到理想浓度(1000~2000个/μL)。 - 10X 标记 cDNA 片段
含有 barcode 信息的凝胶珠与细胞和酶的混合物结合,进入储液器中被油分隔开,形成GEMs(Gel Beads-In-Emulsions)。之后,凝胶珠溶解释放含有Barcode序列的捕获序列,逆转录 cDNA 片段,并对样本进行标记。将凝胶珠破碎并打碎油滴,以 cDNA 为模板进行 PCR 扩增。将所有GEMs的产物混合,构建标准测序文库。 - 标准测序文库建库
首先将 cDNA 酶切打断成 200~300bp 左右的片段,然后经过末端修复、加A尾、测序接头 P5 、P7和sample index等常规二代测序文库构建步骤,最后进行 PCR 扩增得到 DNA 文库。 - 文库测序
利用Illumina测序平台的PE150测序模式对建好的文库进行高通量测序。
2.2 分析流程
 |
| Fig 2-2-1 10x单细胞分析流程图 |
3 测序数据质控和表达量定量
3.1 测序数据基本质控
使用cellranger[1],我们可以对测序质量进行质控,去除测序质量低的reads,并对每个样本测的reads数和测序质量进行初步统计。
| Sample | Number of Reads | Valid Barcodes | Sequencing Saturation | Q30 Bases in Barcode | Q30 Bases in RNA Read | Q30 Bases in UMI |
|---|---|---|---|---|---|---|
| NP | 270,139,313 | 96.8% | 61.6% | 94.9% | 89.6% | 94.3% |
| NPM | 320,541,930 | 97.3% | 53.3% | 95.2% | 90.4% | 94.5% |
| PBS | 318,068,461 | 96.7% | 69.1% | 95.0% | 90.1% | 94.3% |
3.2 数据定量
使用cellranger,我们将reads与参考基因组进行比对,将reads注释为特定基因;再对UMI进行修正和统计后,获得未过滤的feature-barcode矩阵;根据未过滤的feature-barcode矩阵,cellranger对数据中的细胞和非细胞进行识别和区分,并绘制为rank-plot图,直观体现有效细胞鉴定结果。
| Sample | Estimated Number of Cells | Fraction Reads in Cells | Mean Reads per Cell | Median Genes per Cell | Total Genes Detected | Median UMI Counts per Cell | Reads Mapped Confidently to Genome | Reads Mapped Confidently to Intergenic Regions | Reads Mapped Confidently to Intronic Regions | Reads Mapped Confidently to Exonic Regions | Reads Mapped Confidently to Transcriptome |
|---|---|---|---|---|---|---|---|---|---|---|---|
| NP | 10,865 | 90.4% | 24,863 | 1,231 | 16,452 | 2,808 | 88.8% | 12.9% | 22.2% | 53.7% | 50.5% |
| NPM | 16,359 | 88.7% | 19,594 | 1,124 | 16,541 | 2,402 | 91.7% | 8.1% | 19.0% | 64.5% | 61.0% |
| PBS | 12,489 | 91.2% | 25,467 | 938 | 16,135 | 2,349 | 89.2% | 12.9% | 23.8% | 52.5% | 49.0% |
- NP有效细胞
- NPM有效细胞
- PBS有效细胞
Fig 3-2-1 有效细胞鉴定图
各样本质控、定量结果报告:
- NP : 1.Expression/CellRanger_Report/CellRanger.NP.result.html
- NPM : 1.Expression/CellRanger_Report/CellRanger.NPM.result.html
- PBS : 1.Expression/CellRanger_Report/CellRanger.PBS.result.html
3.3 最终鉴定细胞表达量矩阵
基于UMI修正和有效细胞鉴定后的结果,我们可以使用UMI条数对基因进行定量,获得如下的细胞-基因表达量定量结果。
| GeneID | Name | AAACCCAAGATACATG-1 | AAACCCAAGATGAAGG-1 | AAACCCAAGCACTCAT-1 | AAACCCAAGCATTTCG-1 | AAACCCAAGCCGGAAT-1 | AAACCCAAGCTTAAGA-1 | AAACCCAAGCTTACGT-1 | AAACCCAAGTCGCTAT-1 | AAACCCACATACTGAC-1 |
|---|---|---|---|---|---|---|---|---|---|---|
| ENSMUSG00000114212 | Gm47985 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000114943 | Gm8947 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000114694 | Gm47995 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000114582 | 3110040M04Rik | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000114591 | Gm47996 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000051285 | Pcmtd1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 2 | 0 |
| ENSMUSG00000026312 | Cdh7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000039748 | Exo1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000104158 | Gm38100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000057363 | Uxs1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000047216 | Cdh19 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000038702 | Dsel | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000033021 | Gmppa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000055214 | Pld5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000078184 | Rbm8a2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000033007 | Asic4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000070695 | Cntnap5a | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000025909 | Sntg1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000094429 | Gm19965 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000100265 | Gm28363 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
备注:由于单个细胞在某个瞬间,只有小部分基因表达,因此表中大量基因UMI丰度为0。
UMI定量总表文件:
- NP : 1.Expression/expressions/NP/expression.xls
- NPM : 1.Expression/expressions/NPM/expression.xls
- PBS : 1.Expression/expressions/PBS/expression.xls
4 单细胞亚群分类
在cellranger完成基因表达量鉴定后,我们将表达量矩阵转入Seurat[2]进行后续的分析。
4.1 非正常细胞的进一步过滤
cellranger的细胞过滤是根据基因表达量进行自动识别,会有部分非正常细胞残留,所以在进行亚群分类之前,我们需要对非正常细胞进行进一步过滤。
首先检测各样本中含有多个细胞的GEM。利用DoubletFinder[3]计算GEM为多胞的概率(pANN值),然后基于10X官方给出的有效细胞数(cellranger过滤后)与多胞率之间的关系计算各样本多胞率,确定各样本多胞过滤阈值,依次进行多胞过滤。
- NP
- NPM
- PBS
| Cells | pANN | classifications |
|---|---|---|
| NP_AAACCCAAGATACATG | 0.111111111111111 | Singlet |
| NP_AAACCCAAGATGAAGG | 0.347222222222222 | Doublet |
| NP_AAACCCAAGCACTCAT | 0.111111111111111 | Singlet |
| NP_AAACCCAAGCATTTCG | 0.0833333333333333 | Singlet |
| NP_AAACCCAAGCCGGAAT | 0.0555555555555556 | Singlet |
| NP_AAACCCAAGCTTAAGA | 0.0138888888888889 | Singlet |
| NP_AAACCCAAGCTTACGT | 0.0277777777777778 | Singlet |
| NP_AAACCCAAGTCGCTAT | 0.541666666666667 | Doublet |
| NP_AAACCCACATACTGAC | 0.0138888888888889 | Singlet |
| NP_AAACCCACATCAACCA | 0.0833333333333333 | Singlet |
| Cells | pANN | classifications |
|---|---|---|
| NPM_AAACCCAAGATTGCGG | 0.152679830747532 | Singlet |
| NPM_AAACCCAAGCACACAG | 0.277856135401975 | Singlet |
| NPM_AAACCCAAGCCATTCA | 0.190409026798307 | Singlet |
| NPM_AAACCCAAGTCATGCT | 0.415373765867419 | Doublet |
| NPM_AAACCCAAGTCCCAGC | 0.0624118476727786 | Singlet |
| NPM_AAACCCACAGCATGCC | 0.138222849083216 | Singlet |
| NPM_AAACCCACAGGACATG | 0.175599435825106 | Singlet |
| NPM_AAACCCAGTAGGCTGA | 0.321932299012694 | Singlet |
| NPM_AAACCCAGTAGTTCCA | 0.21015514809591 | Singlet |
| NPM_AAACCCAGTATGCAAA | 0.0719322990126939 | Singlet |
| Cells | pANN | classifications |
|---|---|---|
| PBS_AAACCCAAGAAGCTGC | 0.0240963855421687 | Singlet |
| PBS_AAACCCACAATAGGAT | 0.192771084337349 | Singlet |
| PBS_AAACCCACACAGCATT | 0 | Singlet |
| PBS_AAACCCACACCAGTAT | 0.0602409638554217 | Singlet |
| PBS_AAACCCACACCTTCCA | 0.0120481927710843 | Singlet |
| PBS_AAACCCACACGGCCAT | 0.0481927710843374 | Singlet |
| PBS_AAACCCAGTGCATACT | 0.108433734939759 | Singlet |
| PBS_AAACCCATCCTCGCAT | 0.0481927710843374 | Singlet |
| PBS_AAACCCATCCTGTTAT | 0.0843373493975904 | Singlet |
| PBS_AAACGAAAGCATACTC | 0 | Singlet |
Tab 4-1-1 多胞检测结果统计表
- NP
- NPM
- PBS
Fig 4-1-1 多胞概率分布tSNE图
- NP
- NPM
- PBS
Fig 4-1-2 多胞分布tSNE图
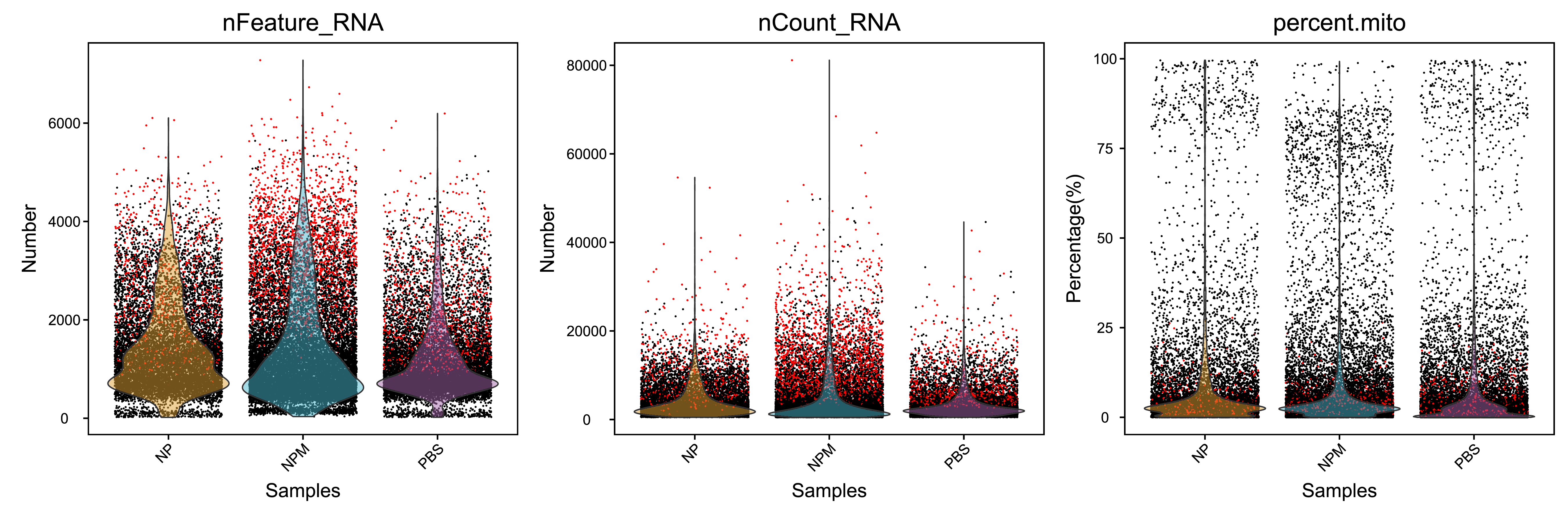
除此以外,我们对以下指标进行过滤:
- 单细胞中鉴定到的基因数量(200.0-4500.0)。对于同一种细胞来说,表达基因的数量一般维持在一定范围内,如果该值过高,可能是一个GEM中包裹了多种细胞类型,这样的barcode应该剔除
- 单细胞中UMI的总数(小于22000.0)。单个细胞中可以存在的mRNA总量是有限的,如果UMI总数过高,则可能是两个或两个以上的细胞进入同一个GEM中,这样的细胞应该剔除
- 单细胞中线粒体基因表达量比例(小于32.0%)。细胞凋亡通常伴随着线粒体基因的高表达,所以线粒体基因的高表达意味着细胞状态不佳,这些细胞在实验过程中受到了不良刺激,不利于后续分析反应真实的细胞情况,这样的细胞应该剔除
| Samples | before_filter_num | after_filter_num | pct | before_filter_median_UMI_per_cell | after_filter_median_UMI_per_cell | before_filter_median_genes_per_cell | after_filter_median_genes_per_cell | before_filter_median_MT_per_cell | after_filter_median_MT_per_cell |
|---|---|---|---|---|---|---|---|---|---|
| NP | 10865 | 9294 | 85.54% | 2808 | 2765.5 | 1231 | 1219 | 3.0808729139923 | 2.90780504371868 |
| NPM | 16359 | 13033 | 79.67% | 2402 | 2188 | 1124 | 1049 | 2.97004132231405 | 2.76990871891722 |
| PBS | 12489 | 10694 | 85.63% | 2349 | 2267 | 938 | 897 | 2.37005749149361 | 2.21095657188905 |
 |
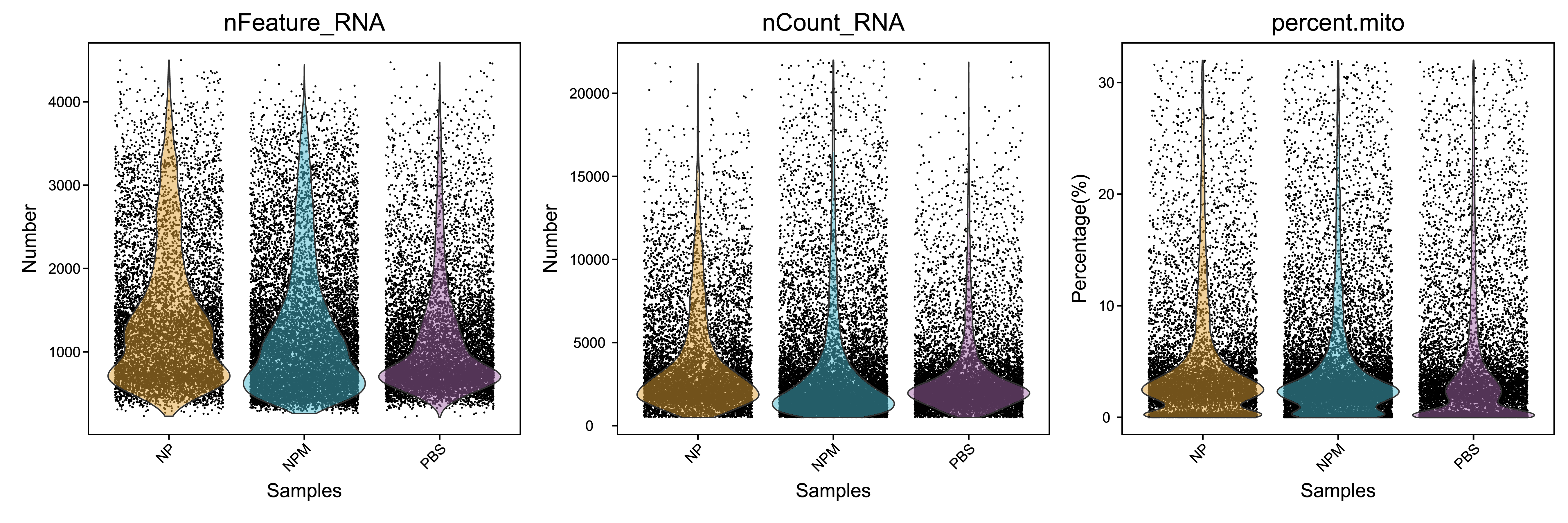 |
| Fig 4-1-3 过滤前后各个样本细胞基本信息的分布图 |
- nCount与nFeature的关系
- nCount与pMito的关系
Fig 4-1-4 过滤前后各个样本细胞基本信息的分布散点图
4.2 单细胞亚群分类
在去除低质量细胞后,我们利用Harmony[4]进行数据合并以及批次效应矫正。首先对合并后的数据进行PCA降维,Harmony采用soft k-means clustering算法对降维后的数据进行聚类,将细胞概率性的分配给cluster,使每个cluster内数据集的多样性最大化;然后计算每个cluster内所有数据集的全局中心,以及每个特定数据集的中心;最后在每个cluster内,基于中心为每个数据集计算校正因子,对细胞进行校正使其向中心聚集;不断重复以上步骤,直到聚类效果趋于稳定。
| Cluster | Cells number | Median Features per Cell | Median Counts per Cell |
|---|---|---|---|
| 0 | 7651 | 666 | 1732 |
| 1 | 6586 | 2055.5 | 5226.5 |
| 2 | 3537 | 1057 | 2371 |
| 3 | 2826 | 930.5 | 2056 |
| 4 | 2025 | 1066 | 2107 |
| 5 | 1986 | 1056 | 2379 |
| 6 | 1537 | 1118 | 2327 |
| 7 | 1247 | 1323 | 2533 |
| 8 | 885 | 1170 | 2448 |
| 9 | 868 | 1697 | 4899 |
| 10 | 775 | 1801 | 5471 |
| 11 | 749 | 1212 | 2997 |
| 12 | 701 | 1197 | 2600 |
| 13 | 315 | 1546 | 4094 |
| 14 | 315 | 1226 | 2610 |
| 15 | 287 | 3155 | 13100 |
| 16 | 208 | 1948.5 | 5467.5 |
| 17 | 136 | 1173 | 2535.5 |
| 18 | 131 | 959 | 1547 |
| 19 | 102 | 2281.5 | 6718 |
| 20 | 58 | 1170 | 2734.5 |
| 21 | 54 | 1038.5 | 4533.5 |
| 22 | 42 | 596.5 | 1134 |
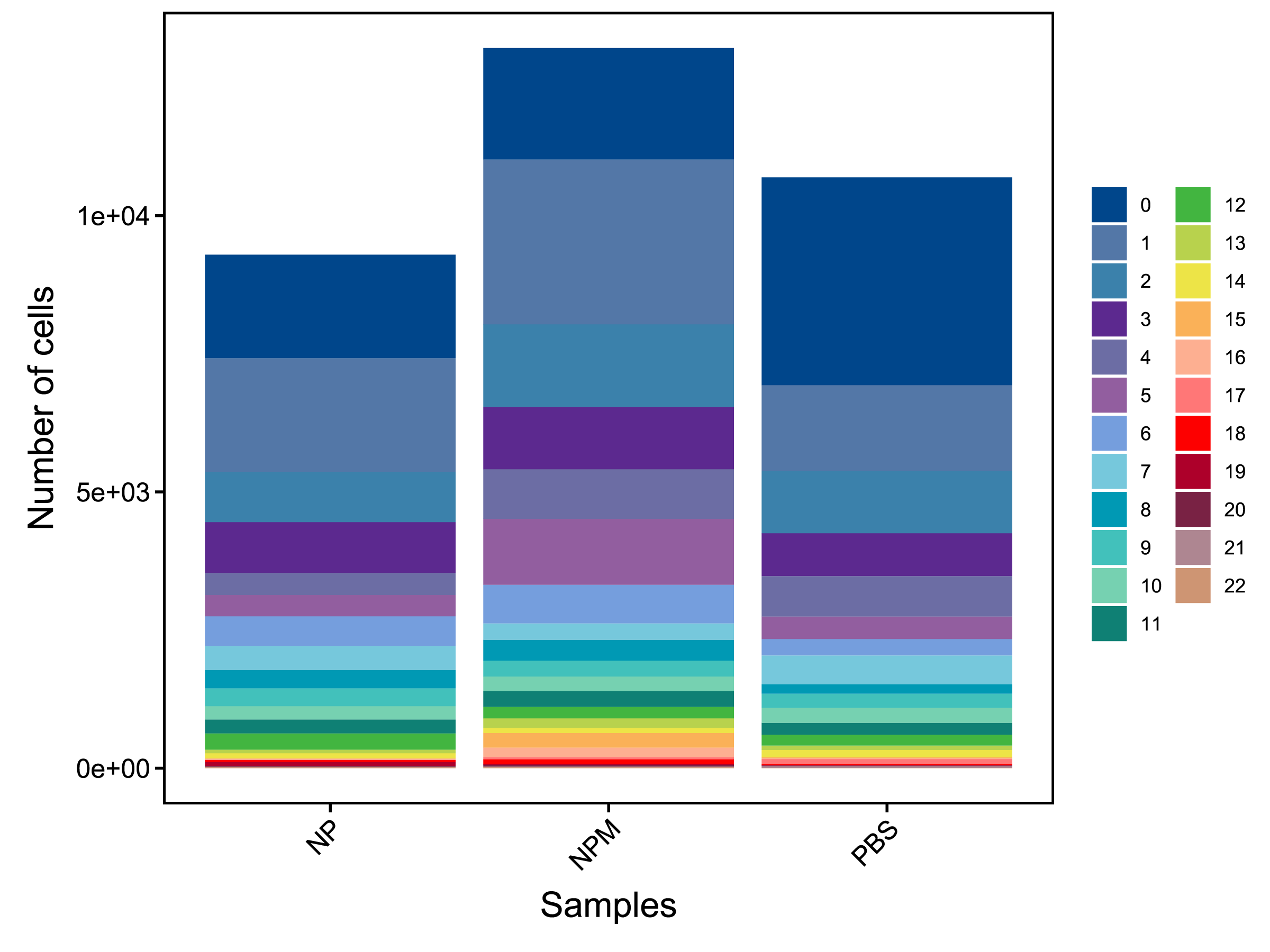
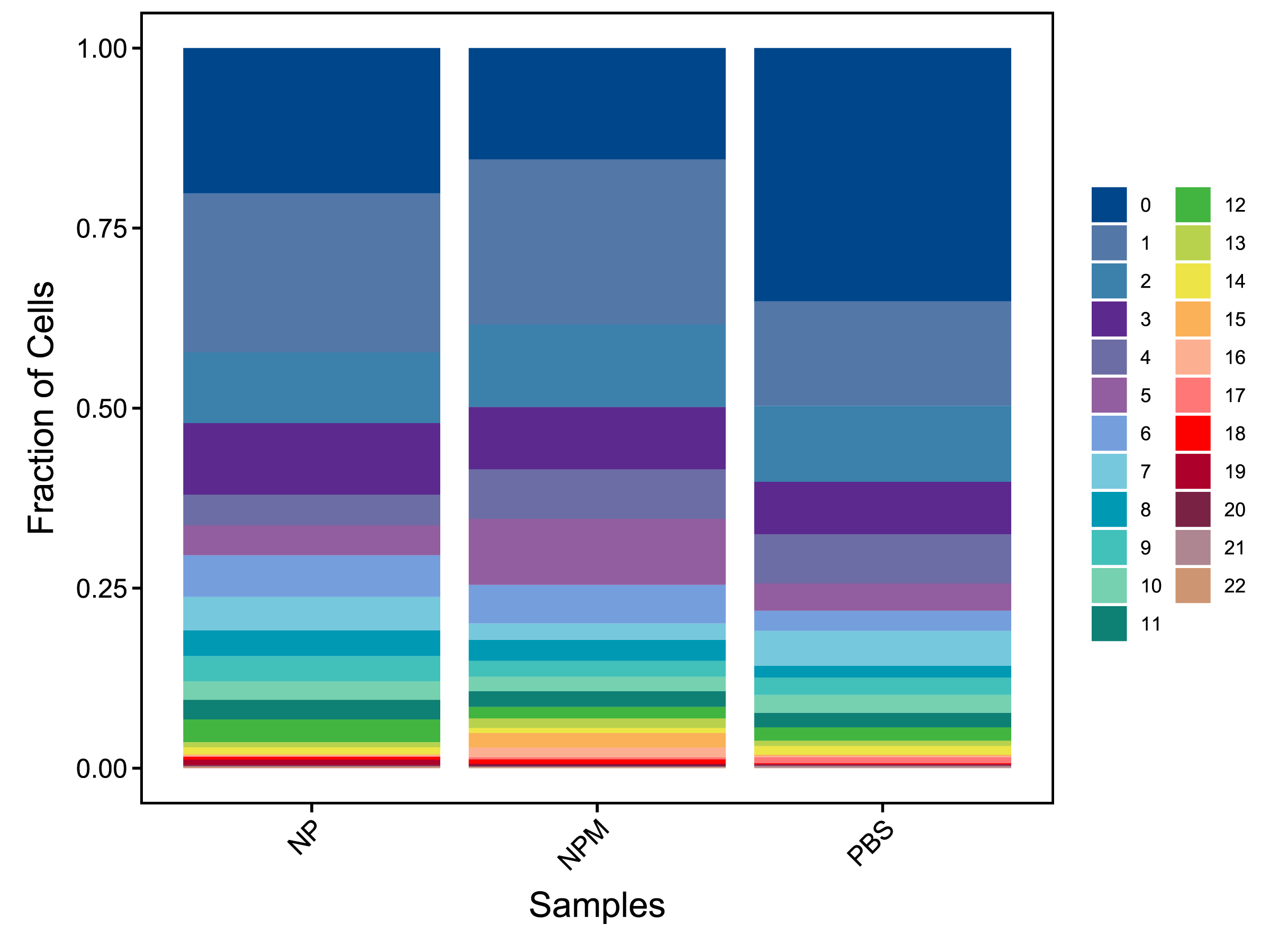
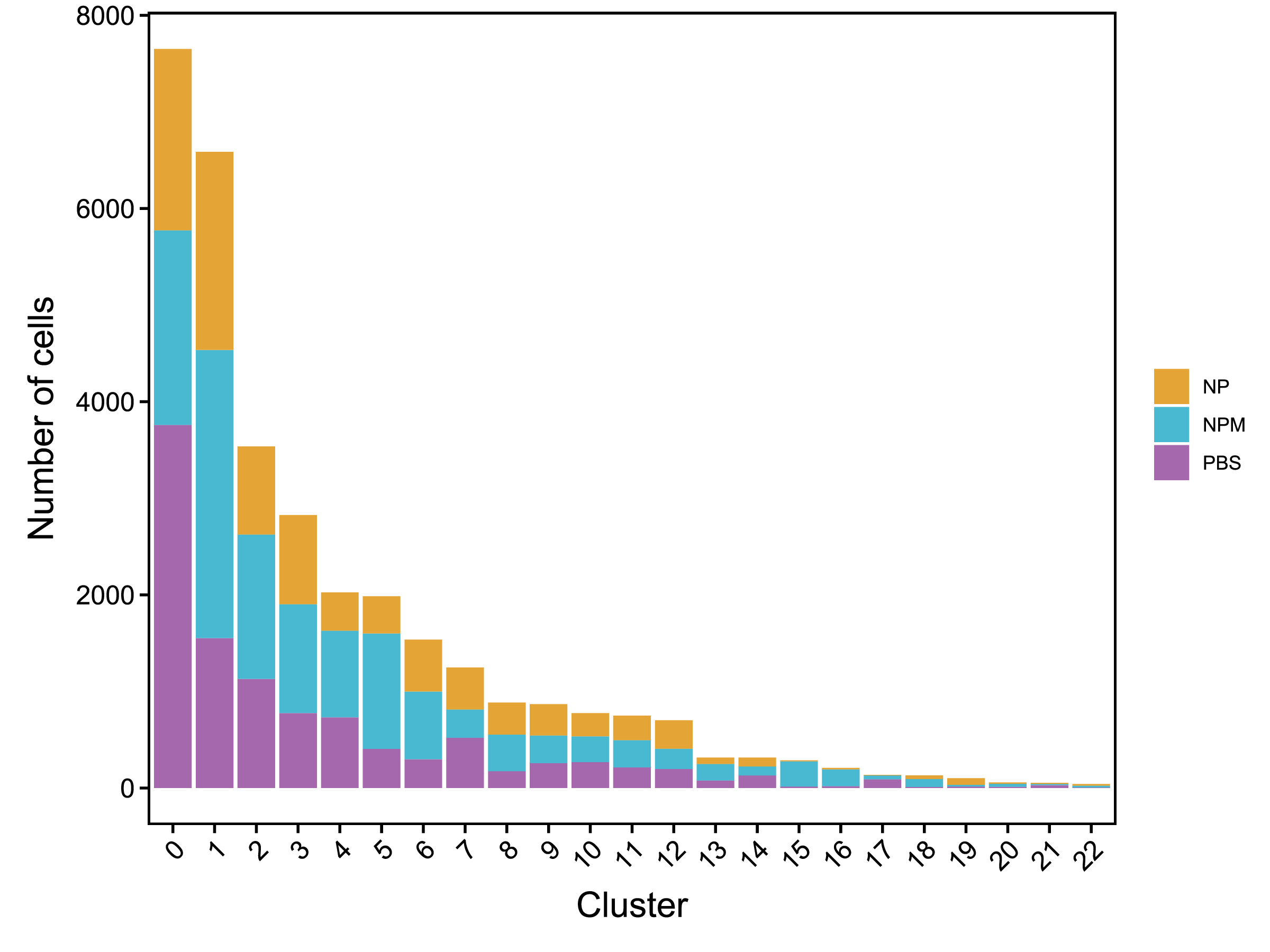
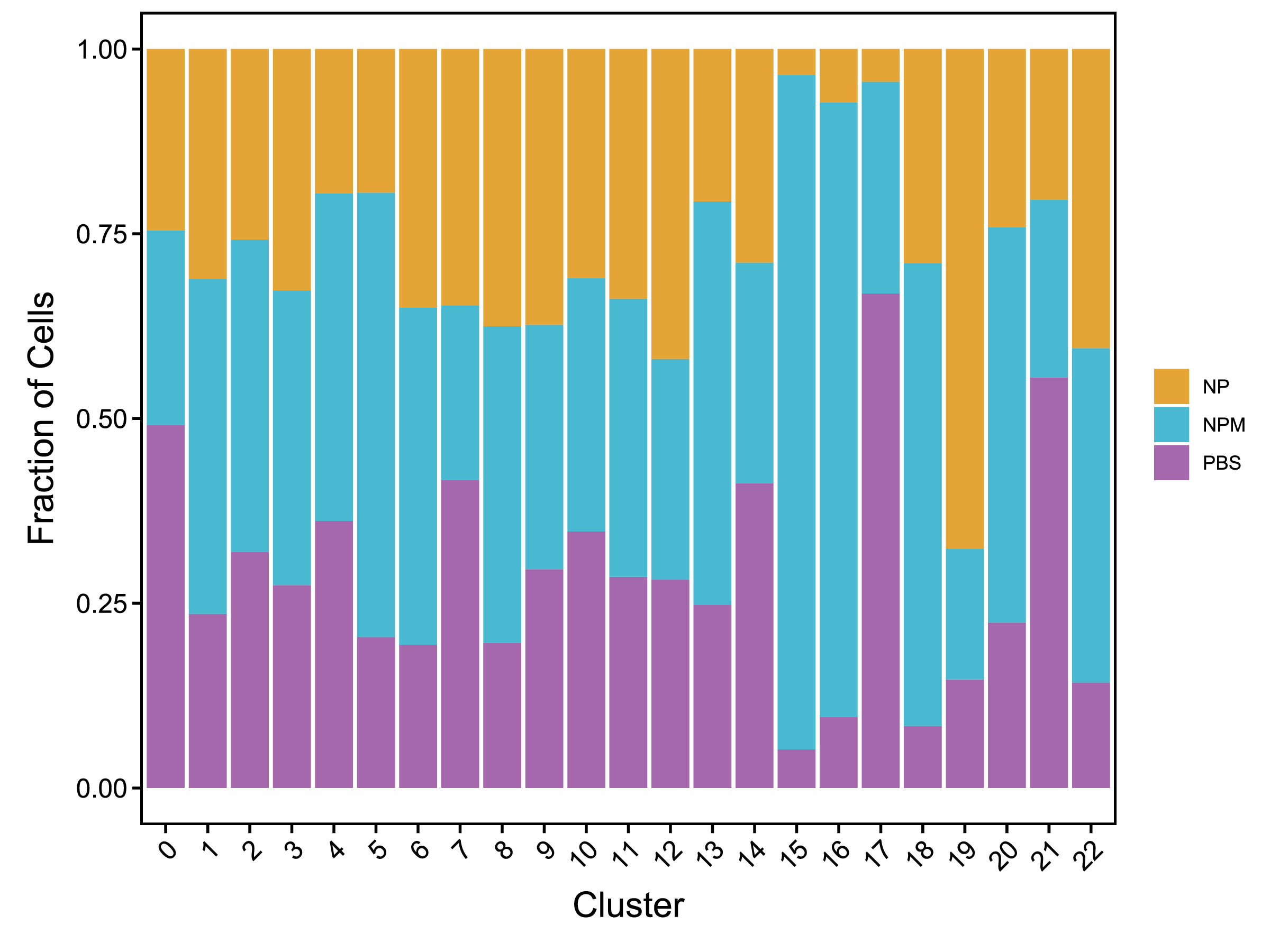
| Cluster | NP | NPM | PBS |
|---|---|---|---|
| Total | 9294 (100%) | 13033 (100%) | 10694 (100%) |
| 0 | 1876 (20.19%) | 2015 (15.46%) | 3760 (35.16%) |
| 1 | 2051 (22.07%) | 2983 (22.89%) | 1552 (14.51%) |
| 2 | 912 (9.81%) | 1496 (11.48%) | 1129 (10.56%) |
| 3 | 923 (9.93%) | 1127 (8.65%) | 776 (7.26%) |
| 4 | 396 (4.26%) | 897 (6.88%) | 732 (6.84%) |
| 5 | 386 (4.15%) | 1194 (9.16%) | 406 (3.8%) |
| 6 | 538 (5.79%) | 701 (5.38%) | 298 (2.79%) |
| 7 | 433 (4.66%) | 294 (2.26%) | 520 (4.86%) |
| 8 | 332 (3.57%) | 379 (2.91%) | 174 (1.63%) |
| 9 | 324 (3.49%) | 287 (2.2%) | 257 (2.4%) |
| 10 | 240 (2.58%) | 266 (2.04%) | 269 (2.52%) |
| 11 | 253 (2.72%) | 282 (2.16%) | 214 (2%) |
| 12 | 294 (3.16%) | 209 (1.6%) | 198 (1.85%) |
| 13 | 65 (0.7%) | 172 (1.32%) | 78 (0.73%) |
| 14 | 91 (0.98%) | 94 (0.72%) | 130 (1.22%) |
| 15 | 10 (0.11%) | 262 (2.01%) | 15 (0.14%) |
| 16 | 15 (0.16%) | 173 (1.33%) | 20 (0.19%) |
| 17 | 6 (0.06%) | 39 (0.3%) | 91 (0.85%) |
| 18 | 38 (0.41%) | 82 (0.63%) | 11 (0.1%) |
| 19 | 69 (0.74%) | 18 (0.14%) | 15 (0.14%) |
| 20 | 14 (0.15%) | 31 (0.24%) | 13 (0.12%) |
| 21 | 11 (0.12%) | 13 (0.1%) | 30 (0.28%) |
| 22 | 17 (0.18%) | 19 (0.15%) | 6 (0.06%) |
 |
 |
|
| Fig 4-2-1 各样本中各亚群细胞数量堆叠图 | Fig 4-2-2 各样本中各亚群细胞数量百分比堆叠图 | |
 |
 |
|
| Fig 4-2-3 各亚群中各个样本细胞数量堆叠图 | Fig 4-2-4 各亚群中各个样本细胞数量百分比堆叠图 | |
进一步,我们计算两个细胞亚群之间相关性并绘制成热图。图中具有高度相关性的两个细胞亚群具有比较相似的基因表达模式,可能是同一种细胞类型。这张相关性热图为人工细胞亚群鉴定提供了一定的指导作用。
 |
| Fig 4-2-5 各亚群相关性热图 |
基因在各个亚群中表达量的均值表:2.Cluster/2.cluster/AllGene.avg_exp.annot.xls
| Gene_ID | Gene_name | Cluster 0 | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 | Cluster 7 | Cluster 8 | Cluster 9 | Cluster 10 | Cluster 11 | Cluster 12 | Cluster 13 | Cluster 14 | Cluster 15 | Cluster 16 | Cluster 17 | Cluster 18 | Cluster 19 | Cluster 20 | Cluster 21 | Cluster 22 | Description | KEGG_A_class | KEGG_B_class | Pathway | K_ID | GO Component | GO Function | GO Process |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ENSMUSG00000114212 | Gm47985 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | predicted gene, 47985 [Source:MGI Symbol;Acc:MGI:6097275] | - | - | - | - | - | - | - |
| ENSMUSG00000114943 | Gm8947 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | predicted gene 8947 [Source:MGI Symbol;Acc:MGI:3648958] | - | - | - | - | GO:0005575//cellular_component | GO:0003674//molecular_function | GO:0008150//biological_process |
| ENSMUSG00000114694 | Gm47995 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | predicted gene, 47995 [Source:MGI Symbol;Acc:MGI:6097291] | - | - | - | - | - | - | - |
| ENSMUSG00000114582 | 3110040M04Rik | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | RIKEN cDNA 3110040M04 gene [Source:MGI Symbol;Acc:MGI:1920426] | - | - | - | - | GO:0005575//cellular_component | GO:0003674//molecular_function | GO:0008150//biological_process |
| ENSMUSG00000114591 | Gm47996 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | predicted gene, 47996 [Source:MGI Symbol;Acc:MGI:6097293] | - | - | - | - | - | - | - |
| ENSMUSG00000051285 | Pcmtd1 | 0.662869921897392 | 0.734556819121962 | 1.27655215560597 | 0.938655786498966 | 1.06831924926472 | 0.706323152823109 | 1.12246829653249 | 1.33445405642604 | 0.780967405974505 | 0.57236029710819 | 2.04148202689669 | 0.875757751326453 | 0.47773797491339 | 0.606332031006227 | 1.19209850482978 | 0.651353279406802 | 0.723067106451562 | 0.834568624202413 | 1.94749313620517 | 0.855228950072604 | 0.571673388205311 | 0.0672587013604373 | 0.030977782734223 | protein-L-isoaspartate (D-aspartate) O-methyltransferase domain containing 1 [Source:MGI Symbol;Acc:MGI:2441773] | - | - | - | - | GO:0005737//cytoplasm;GO:0016020//membrane | GO:0004719//protein-L-isoaspartate (D-aspartate) O-methyltransferase activity;GO:0008168//methyltransferase activity;GO:0016740//transferase activity | GO:0006464//cellular protein modification process;GO:0006479//protein methylation;GO:0032259//methylation |
| ENSMUSG00000026312 | Cdh7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | cadherin 7, type 2 [Source:MGI Symbol;Acc:MGI:2442792] | - | - | - | - | GO:0005886//plasma membrane;GO:0005912//adherens junction;GO:0016020//membrane;GO:0016021//integral component of membrane;GO:0016342//catenin complex | GO:0005509//calcium ion binding;GO:0045296//cadherin binding;GO:0046872//metal ion binding | GO:0000902//cell morphogenesis;GO:0007043//cell-cell junction assembly;GO:0007155//cell adhesion;GO:0007156//homophilic cell adhesion via plasma membrane adhesion molecules;GO:0007275//multicellular organism development;GO:0016339//calcium-dependent cell-cell adhesion via plasma membrane cell adhesion molecules;GO:0034332//adherens junction organization;GO:0098609//cell-cell adhesion;GO:0098742//cell-cell adhesion via plasma-membrane adhesion molecules |
| ENSMUSG00000039748 | Exo1 | 8.84315758029278e-04 | 0.00462093446252856 | 0.0139473585452064 | 0.00457005423789775 | 0.0047345868612506 | 0.00636050805465918 | 0.00351520683319848 | 0.0142413133436948 | 0.0263425936701034 | 0.00875280746971783 | 0.00661053220365385 | 0.00326833166376057 | 0 | 0.0983067612973648 | 0.0062714404871655 | 0.00425877963391956 | 0.00435992772983795 | 0 | 0 | 0 | 0 | 0 | 0 | exonuclease 1 [Source:MGI Symbol;Acc:MGI:1349427] | Genetic Information Processing | Replication and repair | ko03430//Mismatch repair | K10746 | GO:0005634//nucleus;GO:0005654//nucleoplasm;GO:0005886//plasma membrane;GO:0016604//nuclear body | GO:0003677//DNA binding;GO:0003682//chromatin binding;GO:0003824//catalytic activity;GO:0004518//nuclease activity;GO:0004519//endonuclease activity;GO:0004527//exonuclease activity;GO:0008409//5'-3' exonuclease activity;GO:0016787//hydrolase activity;GO:0016788//hydrolase activity, acting on ester bonds;GO:0017108//5'-flap endonuclease activity;GO:0035312//5'-3' exodeoxyribonuclease activity;GO:0045145//single-stranded DNA 5'-3' exodeoxyribonuclease activity;GO:0046872//metal ion binding;GO:0048256//flap endonuclease activity;GO:0051908//double-stranded DNA 5'-3' exodeoxyribonuclease activity | GO:0002376//immune system process;GO:0002455//humoral immune response mediated by circulating immunoglobulin;GO:0006139//nucleobase-containing compound metabolic process;GO:0006281//DNA repair;GO:0006298//mismatch repair;GO:0006310//DNA recombination;GO:0006974//cellular response to DNA damage stimulus;GO:0016446//somatic hypermutation of immunoglobulin genes;GO:0045190//isotype switching;GO:0051321//meiotic cell cycle;GO:0090305//nucleic acid phosphodiester bond hydrolysis |
| ENSMUSG00000104158 | Gm38100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | predicted gene, 38100 [Source:MGI Symbol;Acc:MGI:5611328] | Human Diseases;Human Diseases;Human Diseases;Human Diseases;Cellular Processes;Environmental Information Processing;Human Diseases;Cellular Processes;Cellular Processes;Cellular Processes | Neurodegenerative diseases;Neurodegenerative diseases;Infectious diseases;Infectious diseases;Transport and catabolism;Signal transduction;Neurodegenerative disease;Transport and catabolism;Cell growth and death;Transport and catabolism | ko05010//Alzheimer disease;ko05016//Huntington disease;ko05131//Shigellosis;ko05167//Kaposi sarcoma-associated herpesvirus infection;ko04140//Autophagy - animal;ko04371//Apelin signaling pathway;ko05017//Spinocerebellar ataxia;ko04137//Mitophagy - animal;ko04215//Apoptosis - multiple species;ko04136//Autophagy - other eukaryotes | K08334;K08334;K08334;K08334;K08334;K08334;K08334;K08334;K08334;K08334 | GO:0000407//phagophore assembly site;GO:0005737//cytoplasm;GO:0034271//phosphatidylinositol 3-kinase complex, class III, type I;GO:0034272//phosphatidylinositol 3-kinase complex, class III, type II | GO:0005515//protein binding;GO:0044877//protein-containing complex binding | GO:0000045//autophagosome assembly;GO:0006914//autophagy;GO:0006995//cellular response to nitrogen starvation;GO:0008333//endosome to lysosome transport;GO:0042593//glucose homeostasis;GO:0045324//late endosome to vacuole transport;GO:1990172//G protein-coupled receptor catabolic process |
| ENSMUSG00000057363 | Uxs1 | 0.0381420392516556 | 0.451512655411187 | 0.0956403491381509 | 0.132812905608657 | 0.0508737912256211 | 0.254343837614901 | 0.151635851853723 | 0.0903186481270563 | 0.195148330527673 | 0.333412641074248 | 0.0885876481341668 | 0.104218780687596 | 0.406962506531411 | 0.170970591283452 | 0.240371929556019 | 0.228525013696144 | 0.318125239407624 | 0.056977459716936 | 0.221110249417958 | 0.183557243419318 | 0.1027467349432 | 0.089901541935144 | 0.453115859707657 | UDP-glucuronate decarboxylase 1 [Source:MGI Symbol;Acc:MGI:1915133] | Metabolism;Metabolism | Global and overview maps;Carbohydrate metabolism | ko01100//Metabolic pathways;ko00520//Amino sugar and nucleotide sugar metabolism | K08678;K08678 | GO:0005737//cytoplasm;GO:0005739//mitochondrion;GO:0005794//Golgi apparatus;GO:0016020//membrane;GO:0016021//integral component of membrane;GO:0032580//Golgi cisterna membrane;GO:1902494//catalytic complex | GO:0016829//lyase activity;GO:0016831//carboxy-lyase activity;GO:0042802//identical protein binding;GO:0042803//protein homodimerization activity;GO:0048040//UDP-glucuronate decarboxylase activity;GO:0070403//NAD+ binding | GO:0033320//UDP-D-xylose biosynthetic process;GO:0042732//D-xylose metabolic process |
| ENSMUSG00000047216 | Cdh19 | 0 | 0.00352711724978765 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | cadherin 19, type 2 [Source:MGI Symbol;Acc:MGI:3588198] | - | - | - | - | GO:0005886//plasma membrane;GO:0005912//adherens junction;GO:0016020//membrane;GO:0016021//integral component of membrane;GO:0016342//catenin complex | GO:0005509//calcium ion binding;GO:0045296//cadherin binding;GO:0046872//metal ion binding | GO:0000902//cell morphogenesis;GO:0007043//cell-cell junction assembly;GO:0007155//cell adhesion;GO:0007156//homophilic cell adhesion via plasma membrane adhesion molecules;GO:0007275//multicellular organism development;GO:0016339//calcium-dependent cell-cell adhesion via plasma membrane cell adhesion molecules;GO:0034332//adherens junction organization;GO:0098609//cell-cell adhesion;GO:0098742//cell-cell adhesion via plasma-membrane adhesion molecules |
| ENSMUSG00000038702 | Dsel | 0.00467472288487814 | 0.0981681005598211 | 0.0239595647491299 | 0.0568219184495828 | 0.0183393477992502 | 0.136887504487812 | 0.0718446491869953 | 0.0199711588264278 | 0.204742369837188 | 0.147031813531544 | 0.00850748565666588 | 0.0385623925609104 | 0.0347548102539783 | 0.0770174378173598 | 0.0584814206053739 | 0.0761185450465903 | 0.056541721611966 | 0 | 0 | 0.0470711412085454 | 0.155889505518488 | 0 | 0 | dermatan sulfate epimerase-like [Source:MGI Symbol;Acc:MGI:2442948] | - | - | - | - | GO:0005575//cellular_component;GO:0016020//membrane;GO:0016021//integral component of membrane | GO:0008146//sulfotransferase activity;GO:0016853//isomerase activity;GO:0047757//chondroitin-glucuronate 5-epimerase activity | GO:0030204//chondroitin sulfate metabolic process;GO:0030205//dermatan sulfate metabolic process |
| ENSMUSG00000033021 | Gmppa | 0.0131638258465208 | 0.244160244849147 | 0.114110180225217 | 0.140901854084539 | 0.155584228617328 | 0.227053211770298 | 0.213559321574648 | 0.156221464814679 | 0.302371556618129 | 0.194522985626834 | 0.160388142679499 | 0.141362988781968 | 0.283454753181288 | 0.343683067059293 | 0.149420410033586 | 0.198355420134944 | 0.224581734198566 | 0.176347258645555 | 0.252120318925301 | 0.202959977384086 | 0.151217021135075 | 0 | 0.480948750607376 | GDP-mannose pyrophosphorylase A [Source:MGI Symbol;Acc:MGI:1916330] | Metabolism;Metabolism;Metabolism | Global and overview maps;Carbohydrate metabolism;Carbohydrate metabolism | ko01100//Metabolic pathways;ko00520//Amino sugar and nucleotide sugar metabolism;ko00051//Fructose and mannose metabolism | K00966;K00966;K00966 | GO:0005575//cellular_component;GO:0005737//cytoplasm | GO:0003674//molecular_function;GO:0016740//transferase activity;GO:0016779//nucleotidyltransferase activity | GO:0009058//biosynthetic process |
| ENSMUSG00000055214 | Pld5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | phospholipase D family, member 5 [Source:MGI Symbol;Acc:MGI:2442056] | - | - | - | - | GO:0005575//cellular_component;GO:0016020//membrane;GO:0016021//integral component of membrane | GO:0003674//molecular_function;GO:0003824//catalytic activity | GO:0008150//biological_process |
| ENSMUSG00000078184 | Rbm8a2 | 0.00211825484387324 | 0.00465707706971735 | 0.00138623921216698 | 0.00313917723108919 | 0 | 0.00318686501714533 | 0.00613848084363752 | 0.00316966252603085 | 0.00801600707600526 | 0.00136388508668035 | 0.00150229663598226 | 0 | 0 | 0 | 0 | 0 | 0.00468585994901784 | 0 | 0 | 0 | 0 | 0 | 0 | RNA binding motif protein 8A2 [Source:MGI Symbol;Acc:MGI:3612447] | Genetic Information Processing;Genetic Information Processing;Genetic Information Processing | Translation;Transcription;Translation | ko03013//RNA transport;ko03040//Spliceosome;ko03015//mRNA surveillance pathway | K12876;K12876;K12876 | GO:0005634//nucleus;GO:0005681//spliceosomal complex;GO:0005737//cytoplasm;GO:0016607//nuclear speck;GO:0035145//exon-exon junction complex | GO:0003676//nucleic acid binding;GO:0003723//RNA binding;GO:0003729//mRNA binding | GO:0000184//nuclear-transcribed mRNA catabolic process, nonsense-mediated decay;GO:0006396//RNA processing;GO:0006397//mRNA processing;GO:0008380//RNA splicing;GO:0051028//mRNA transport |
| ENSMUSG00000033007 | Asic4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | acid-sensing (proton-gated) ion channel family member 4 [Source:MGI Symbol;Acc:MGI:2652846] | Organismal Systems | Sensory system | ko04750//Inflammatory mediator regulation of TRP channels | K04831 | GO:0005887//integral component of plasma membrane;GO:0016020//membrane;GO:0016021//integral component of membrane | GO:0005272//sodium channel activity;GO:0015280//ligand-gated sodium channel activity | GO:0001662//behavioral fear response;GO:0006811//ion transport;GO:0006814//sodium ion transport;GO:0035725//sodium ion transmembrane transport |
| ENSMUSG00000070695 | Cntnap5a | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | contactin associated protein-like 5A [Source:MGI Symbol;Acc:MGI:3643623] | - | - | - | - | GO:0016020//membrane;GO:0016021//integral component of membrane | GO:0004190//aspartic-type endopeptidase activity | GO:0006508//proteolysis;GO:0007155//cell adhesion |
| ENSMUSG00000025909 | Sntg1 | 0 | 7.05288651417747e-04 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | syntrophin, gamma 1 [Source:MGI Symbol;Acc:MGI:1918346] | - | - | - | - | GO:0005856//cytoskeleton | GO:0005198//structural molecule activity;GO:0005515//protein binding | - |
| ENSMUSG00000094429 | Gm19965 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | predicted gene, 19965 [Source:MGI Symbol;Acc:MGI:5012150] | Human Diseases | Infectious diseases | ko05168//Herpes simplex infection | K09228 | - | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0046872//metal ion binding | GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II |
| ENSMUSG00000100265 | Gm28363 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | predicted gene 28363 [Source:MGI Symbol;Acc:MGI:5579069] | Human Diseases | Infectious diseases | ko05168//Herpes simplex infection | K09228 | - | GO:0000977//RNA polymerase II regulatory region sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0001227//DNA-binding transcription repressor activity, RNA polymerase II-specific;GO:0046872//metal ion binding | GO:0000122//negative regulation of transcription by RNA polymerase II;GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II |
细胞与亚群对照表:2.Cluster/2.cluster/Cells.cluster.list.xls
| Cells | Cluster | Samples |
|---|---|---|
| NP_AAACCCAAGATACATG | 8 | NP |
| NP_AAACCCAAGCACTCAT | 8 | NP |
| NP_AAACCCAAGCATTTCG | 1 | NP |
| NP_AAACCCAAGCCGGAAT | 10 | NP |
| NP_AAACCCAAGCTTAAGA | 0 | NP |
| NP_AAACCCAAGCTTACGT | 0 | NP |
| NP_AAACCCACATCAACCA | 14 | NP |
| NP_AAACCCATCAGATTGC | 19 | NP |
| NP_AAACCCATCATGCCAA | 0 | NP |
| NP_AAACCCATCCCGTGAG | 4 | NP |
| NP_AAACCCATCCGGACGT | 3 | NP |
| NP_AAACGAAAGCAGAAAG | 0 | NP |
| NP_AAACGAAAGTGTTCAC | 11 | NP |
| NP_AAACGAACATCATCTT | 2 | NP |
| NP_AAACGAACATCCTGTC | 0 | NP |
| NP_AAACGAAGTACAGAAT | 7 | NP |
| NP_AAACGAAGTATAGGAT | 3 | NP |
| NP_AAACGAAGTTAATGAG | 0 | NP |
| NP_AAACGAATCATTGGTG | 0 | NP |
| NP_AAACGAATCGCGCCAA | 1 | NP |
4.3 分类结果可视化
基于细胞亚群分类的结果,进一步利用tSNE(tSNE,t-Distributed Stochastic Neighbor Embedding)非线性聚类的方法对单细胞亚群分类结果进行可视化[5]。tSNE 的方法通常对不同亚群细胞的分类结果有更佳的呈现效果(亚群间的隔离更加清晰)。
对所有样本的亚群分类可视化,结果如下:
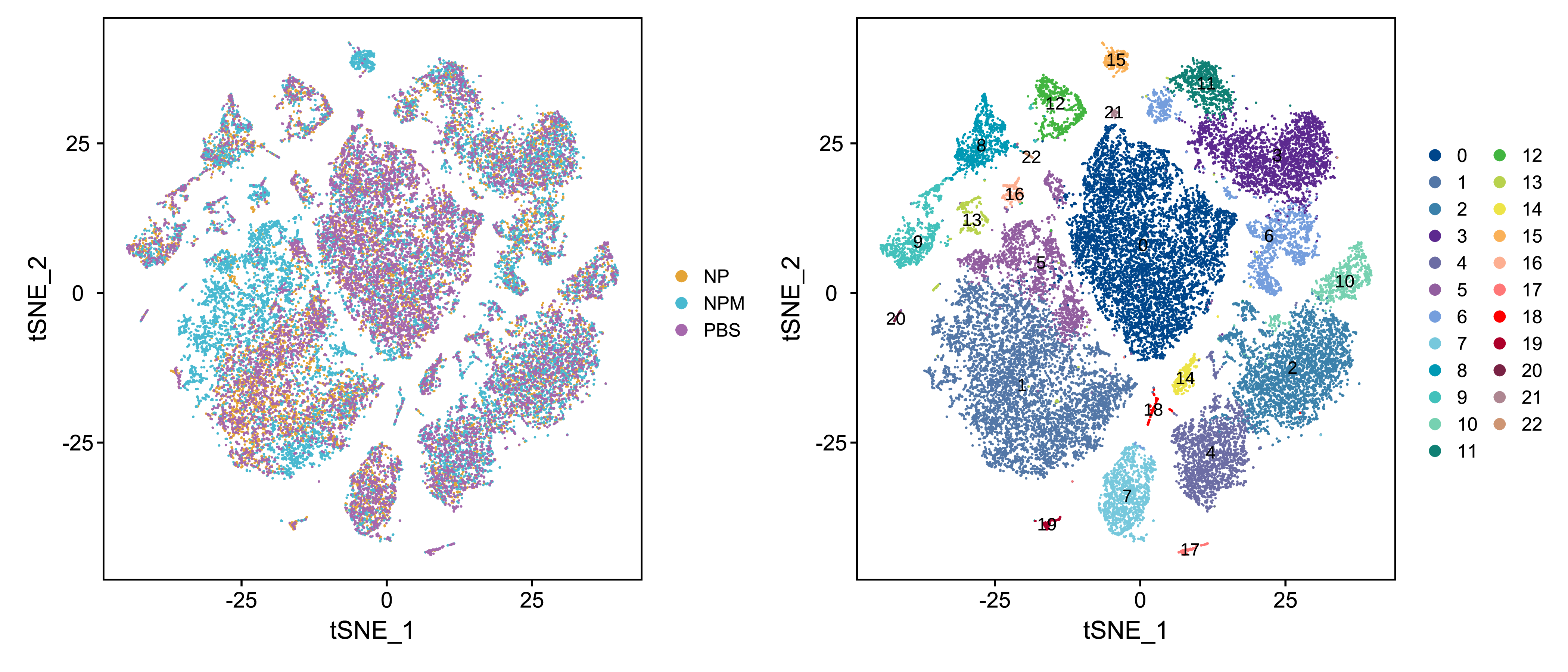 |
| Fig 4-3-1 单细胞亚群分类tSNE图 |
分别对各个样本的亚群分类可视化,结果如下:
- 样本NP单细胞亚群分类tSNE图
- 样本NPM单细胞亚群分类tSNE图
- 样本PBS单细胞亚群分类tSNE图
Fig 4-3-2 各样本单细胞亚群分类tSNE图
4.4 单细胞亚群鉴定
以上单细胞亚群分类是基于细胞表达特征的相似性进行聚类的,每个亚群不具有生物学意义。所以,细胞鉴定一直是很重要但又比较繁琐的步骤。这里,我们使用singleR[6]对所有细胞进行自动化注释,为后续的人工细胞鉴定工作提供参考。
singleR是通过细胞与参考数据库中细胞类型的相似度来自动化鉴定细胞类型,对于相似度较高的细胞类型的注释准确性会降低。所以,singleR的注释结果只能作为辅助手段,最终的细胞亚群鉴定结果依然需要人工鉴定的确认。
| single_clusters | NP | NPM | PBS |
|---|---|---|---|
| Total | 9294 (100%) | 13033 (100%) | 10694 (100%) |
| Adipocytes | 2 (0.02%) | 4 (0.03%) | 1 (0.01%) |
| B cells | 1632 (17.56%) | 2684 (20.59%) | 2178 (20.37%) |
| Cardiomyocytes | 12 (0.13%) | 15 (0.12%) | 6 (0.06%) |
| Dendritic cells | 136 (1.46%) | 495 (3.8%) | 223 (2.09%) |
| Endothelial cells | 33 (0.36%) | 76 (0.58%) | 9 (0.08%) |
| Epithelial cells | 2 (0.02%) | 5 (0.04%) | 1 (0.01%) |
| Erythrocytes | 2 (0.02%) | 0 (0%) | 3 (0.03%) |
| Fibroblasts | 14 (0.15%) | 3 (0.02%) | 0 (0%) |
| Granulocytes | 1967 (21.16%) | 2163 (16.6%) | 3948 (36.92%) |
| Macrophages | 2037 (21.92%) | 4041 (31.01%) | 1371 (12.82%) |
| Microglia | 9 (0.1%) | 1 (0.01%) | 5 (0.05%) |
| Monocytes | 1203 (12.94%) | 1050 (8.06%) | 980 (9.16%) |
| NK cells | 457 (4.92%) | 316 (2.42%) | 562 (5.26%) |
| T cells | 1788 (19.24%) | 2180 (16.73%) | 1407 (13.16%) |
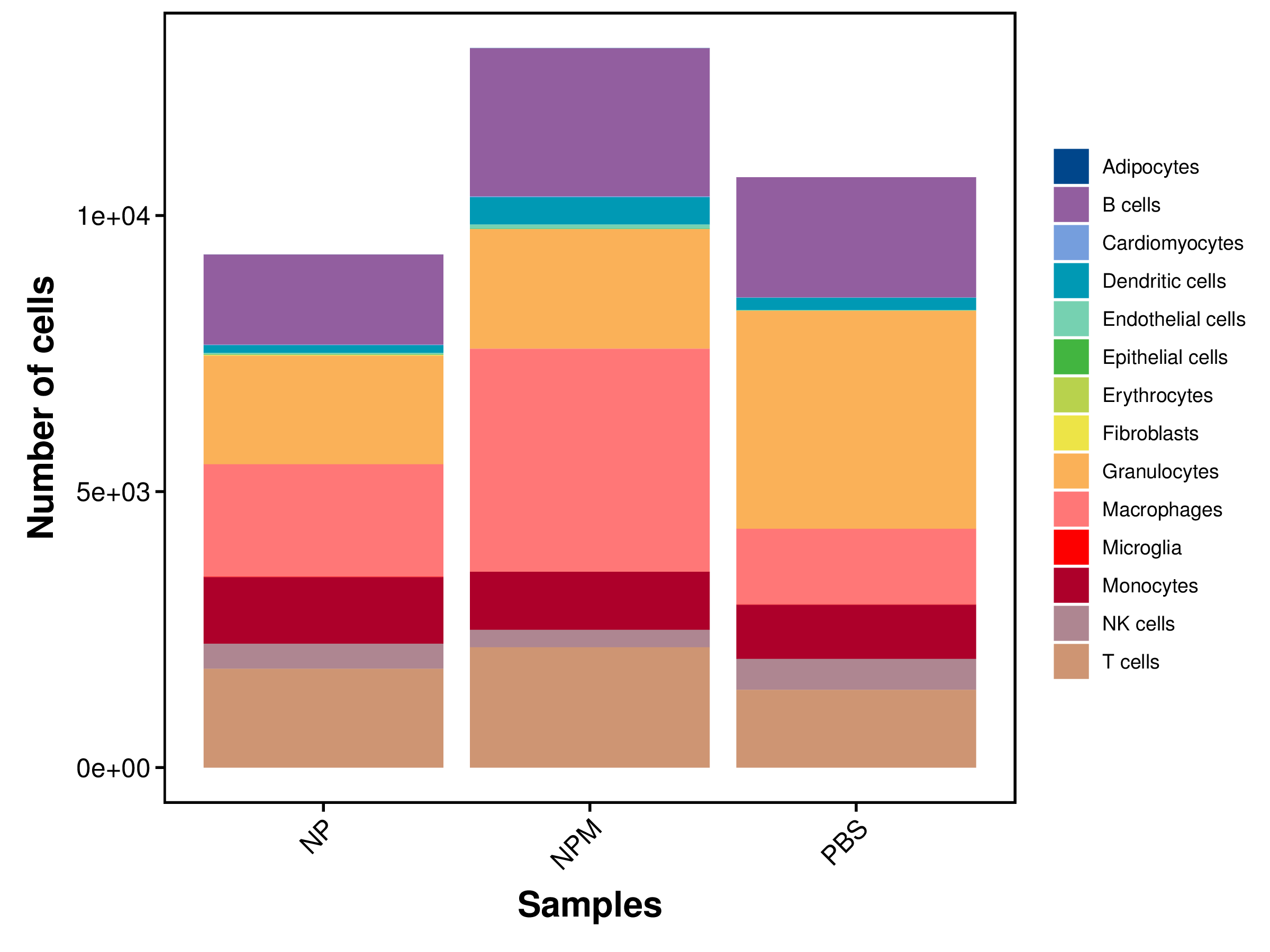 |
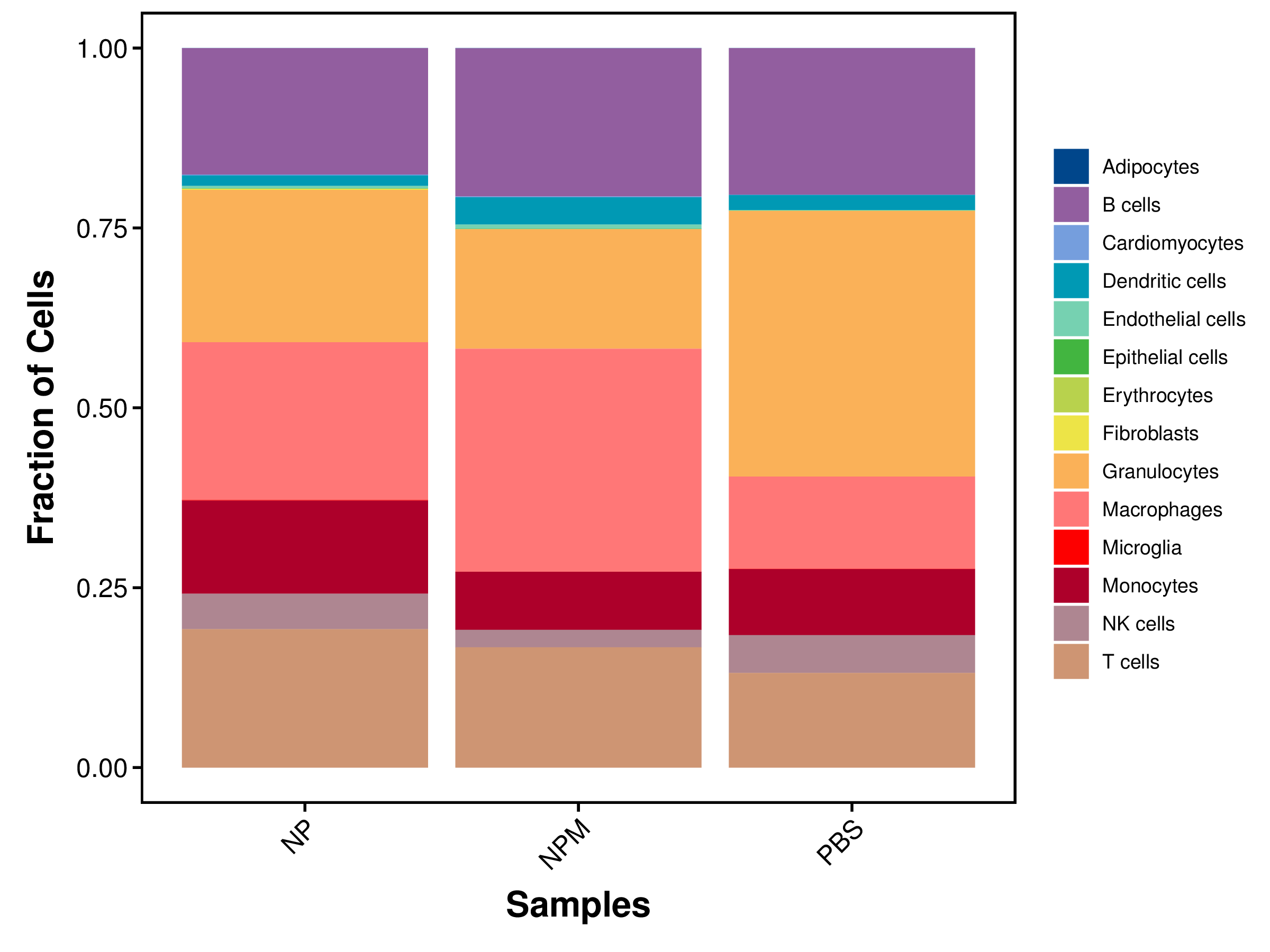 |
|
| Fig 4-4-1 各样本中各细胞类型细胞数量堆叠图 | Fig 4-4-2 各样本中各细胞类型细胞数量百分比堆叠图 | |
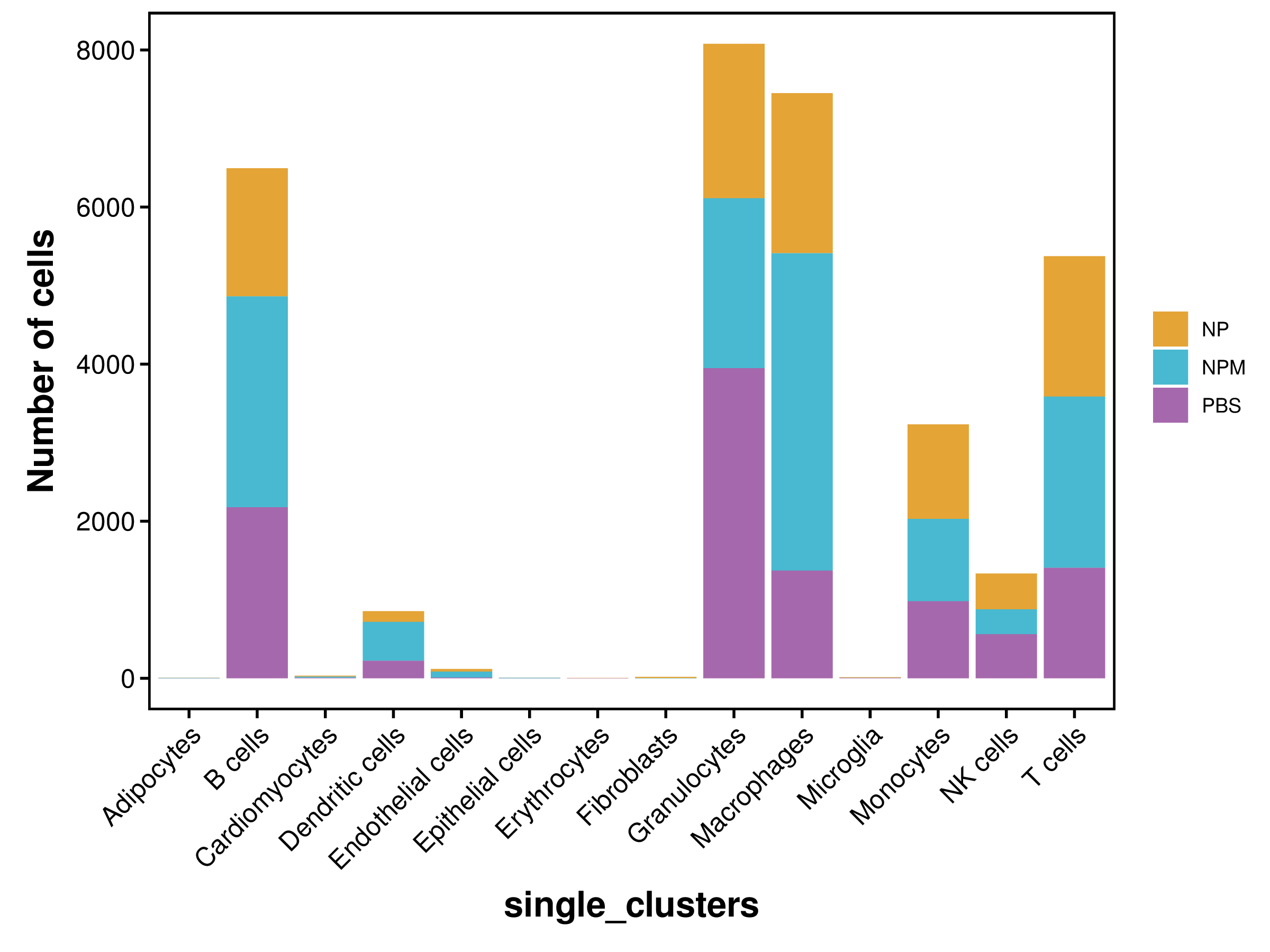 |
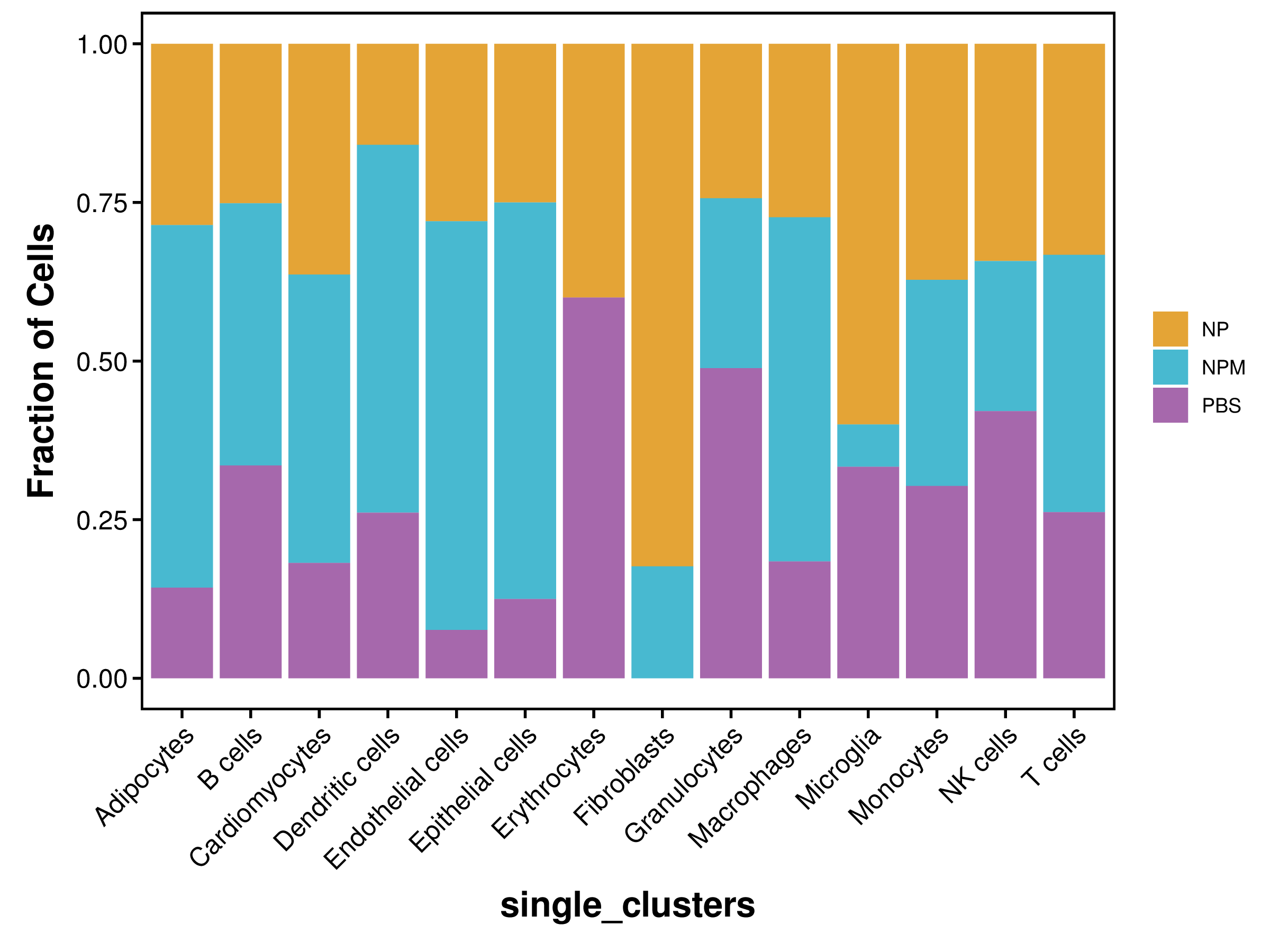 |
|
| Fig 4-4-3 各细胞类型中各个样本细胞数量堆叠图 | Fig 4-4-4 各细胞类型中各个样本细胞数量百分比堆叠图 | |
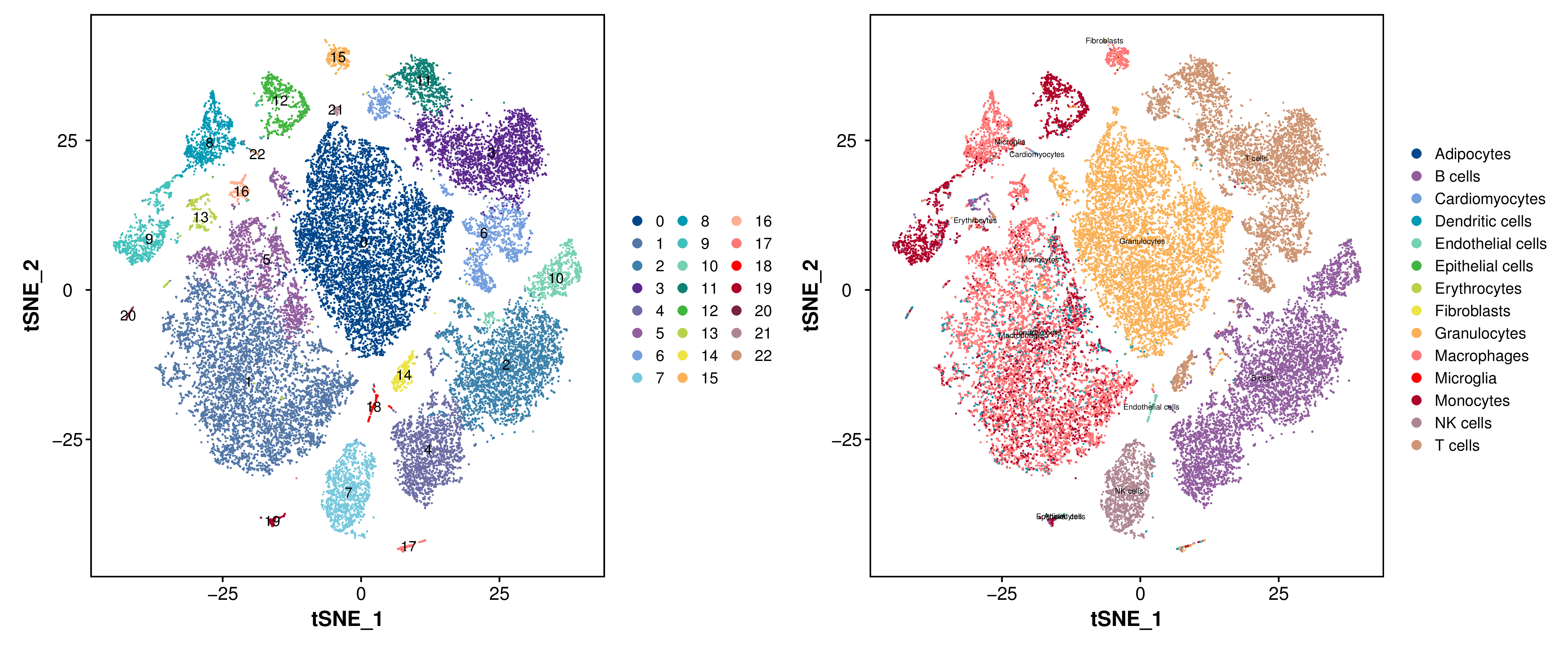 |
| Fig 4-4-5 各细胞类型在tSNE图的分布 |
各细胞亚群中各个细胞类型数量统计表:4.CellAnnotation/Cell.annotation.stat.xls
| Cluster | Cell.annotation (Maximum proportion) | Adipocytes | B cells | Cardiomyocytes | Dendritic cells | Endothelial cells | Epithelial cells | Erythrocytes | Fibroblasts | Granulocytes | Macrophages | Microglia | Monocytes | NK cells | T cells |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Granulocytes(99.14%) | 0(0.00%) | 1(0.01%) | 0(0.00%) | 31(0.41%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 7585(99.14%) | 28(0.37%) | 0(0.00%) | 5(0.07%) | 0(0.00%) | 1(0.01%) |
| 1 | Macrophages(72.70%) | 0(0.00%) | 10(0.15%) | 0(0.00%) | 495(7.52%) | 1(0.02%) | 0(0.00%) | 0(0.00%) | 3(0.05%) | 27(0.41%) | 4788(72.70%) | 0(0.00%) | 1261(19.15%) | 0(0.00%) | 1(0.02%) |
| 2 | B cells(98.39%) | 0(0.00%) | 3480(98.39%) | 0(0.00%) | 2(0.06%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 25(0.71%) | 2(0.06%) | 0(0.00%) | 3(0.08%) | 0(0.00%) | 25(0.71%) |
| 3 | T cells(98.20%) | 0(0.00%) | 6(0.21%) | 0(0.00%) | 9(0.32%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 19(0.67%) | 4(0.14%) | 0(0.00%) | 5(0.18%) | 8(0.28%) | 2775(98.20%) |
| 4 | B cells(98.47%) | 0(0.00%) | 1994(98.47%) | 0(0.00%) | 1(0.05%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 30(1.48%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) |
| 5 | Macrophages(61.08%) | 0(0.00%) | 1(0.05%) | 0(0.00%) | 215(10.83%) | 0(0.00%) | 1(0.05%) | 0(0.00%) | 1(0.05%) | 227(11.43%) | 1213(61.08%) | 1(0.05%) | 324(16.31%) | 0(0.00%) | 3(0.15%) |
| 6 | T cells(95.58%) | 0(0.00%) | 9(0.59%) | 0(0.00%) | 4(0.26%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 3(0.20%) | 1(0.07%) | 0(0.00%) | 1(0.07%) | 50(3.25%) | 1469(95.58%) |
| 7 | NK cells(98.48%) | 0(0.00%) | 4(0.32%) | 0(0.00%) | 7(0.56%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 1228(98.48%) | 8(0.64%) |
| 8 | Macrophages(87.91%) | 0(0.00%) | 4(0.45%) | 0(0.00%) | 5(0.56%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 4(0.45%) | 778(87.91%) | 14(1.58%) | 75(8.47%) | 0(0.00%) | 5(0.56%) |
| 9 | Monocytes(85.83%) | 0(0.00%) | 34(3.92%) | 0(0.00%) | 9(1.04%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 1(0.12%) | 63(7.26%) | 0(0.00%) | 745(85.83%) | 1(0.12%) | 15(1.73%) |
| 10 | B cells(99.35%) | 0(0.00%) | 770(99.35%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 1(0.13%) | 0(0.00%) | 3(0.39%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 1(0.13%) |
| 11 | T cells(99.73%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 1(0.13%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 1(0.13%) | 747(99.73%) |
| 12 | Monocytes(95.58%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 5(0.71%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 17(2.43%) | 7(1.00%) | 0(0.00%) | 670(95.58%) | 0(0.00%) | 2(0.29%) |
| 13 | B cells(37.46%) | 0(0.00%) | 118(37.46%) | 0(0.00%) | 14(4.44%) | 2(0.63%) | 0(0.00%) | 4(1.27%) | 0(0.00%) | 5(1.59%) | 91(28.89%) | 0(0.00%) | 37(11.75%) | 4(1.27%) | 40(12.70%) |
| 14 | T cells(86.35%) | 0(0.00%) | 10(3.17%) | 0(0.00%) | 2(0.63%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 2(0.63%) | 1(0.32%) | 0(0.00%) | 1(0.32%) | 27(8.57%) | 272(86.35%) |
| 15 | Macrophages(90.24%) | 0(0.00%) | 3(1.05%) | 0(0.00%) | 3(1.05%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 13(4.53%) | 5(1.74%) | 259(90.24%) | 0(0.00%) | 4(1.39%) | 0(0.00%) | 0(0.00%) |
| 16 | Macrophages(91.35%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 3(1.44%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 1(0.48%) | 190(91.35%) | 0(0.00%) | 13(6.25%) | 0(0.00%) | 1(0.48%) |
| 17 | Granulocytes(48.53%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 31(22.79%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 66(48.53%) | 2(1.47%) | 0(0.00%) | 20(14.71%) | 15(11.03%) | 2(1.47%) |
| 18 | Endothelial cells(87.02%) | 0(0.00%) | 7(5.34%) | 0(0.00%) | 0(0.00%) | 114(87.02%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 3(2.29%) | 4(3.05%) | 0(0.00%) | 1(0.76%) | 0(0.00%) | 2(1.53%) |
| 19 | Monocytes(40.20%) | 7(6.86%) | 36(35.29%) | 0(0.00%) | 2(1.96%) | 1(0.98%) | 7(6.86%) | 0(0.00%) | 0(0.00%) | 1(0.98%) | 4(3.92%) | 0(0.00%) | 41(40.20%) | 0(0.00%) | 3(2.94%) |
| 20 | Monocytes(44.83%) | 0(0.00%) | 6(10.34%) | 0(0.00%) | 15(25.86%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 9(15.52%) | 0(0.00%) | 26(44.83%) | 1(1.72%) | 1(1.72%) |
| 21 | Granulocytes(100.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 54(100.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) |
| 22 | Cardiomyocytes(78.57%) | 0(0.00%) | 1(2.38%) | 33(78.57%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 0(0.00%) | 5(11.90%) | 0(0.00%) | 1(2.38%) | 0(0.00%) | 2(4.76%) |
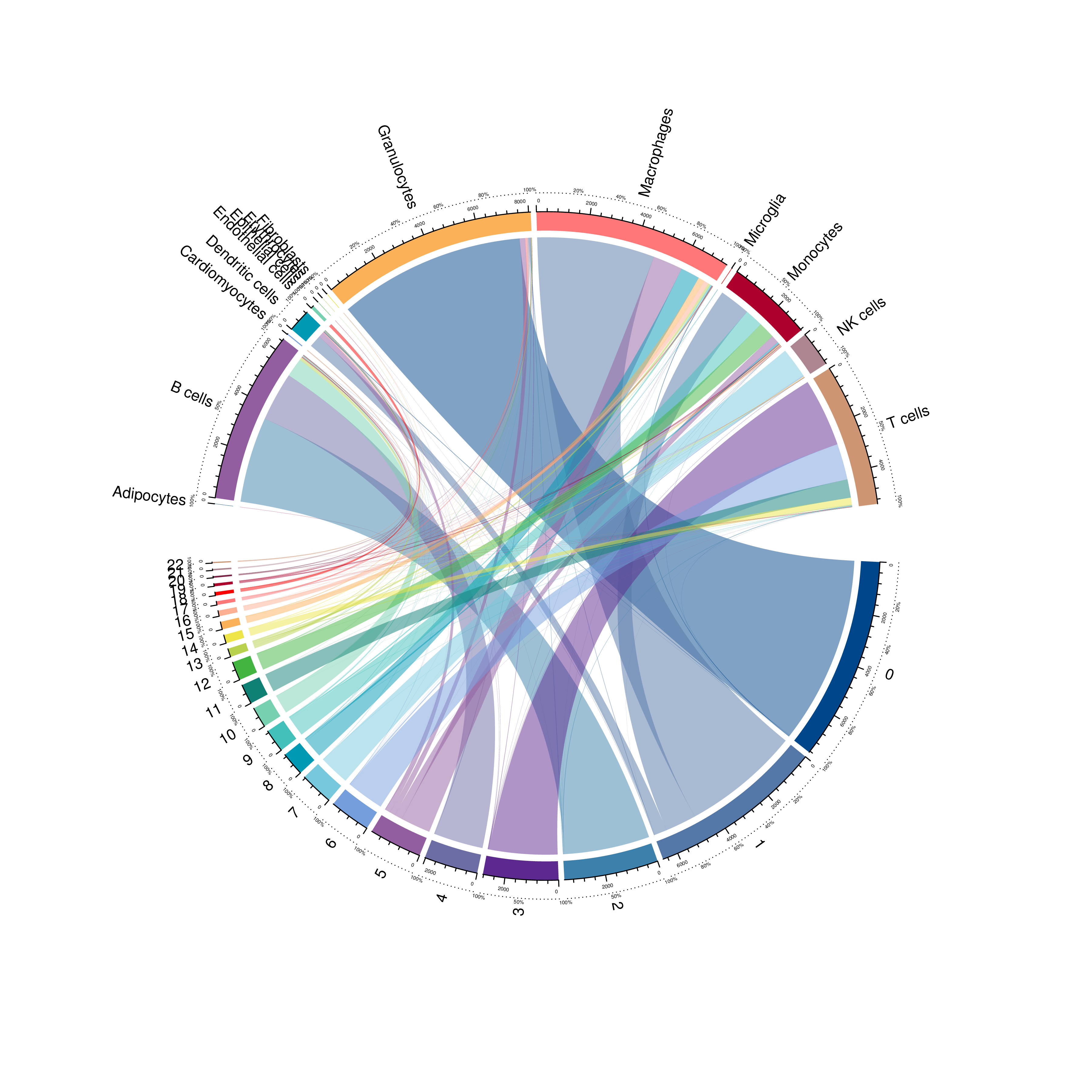 |
| Fig 4-4-6 Seurat分群与singleR细胞鉴定对应circos图 |
通过singleR,我们可以鉴定细胞的细胞类型;通过Seurat,我们可以得到细胞的聚类信息。通过这两个软件,我们可以将一组细胞按照细胞类型和细胞分群两种方式进行聚类。然后,我们计算各个细胞亚群的细胞与各个细胞类型的细胞之间的相关性,并绘制成热图,作为singleR细胞鉴定结果准确性的一个佐证。
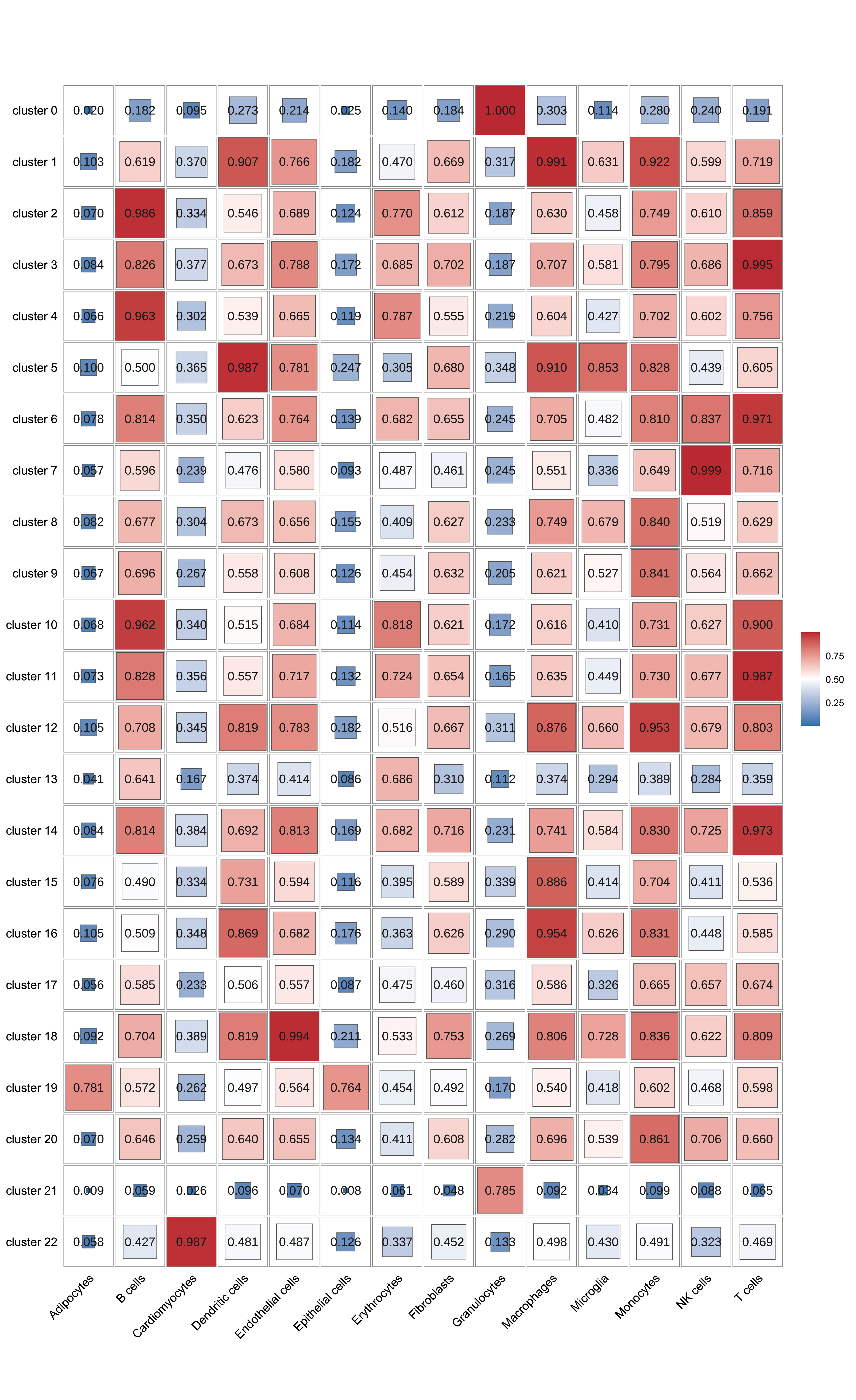 |
| Fig 4-4-7 Seurat分群与singleR鉴定细胞类型相关性热图 |
5 亚群上调表达基因分析
5.1 上调表达基因分析
为了了解各个细胞亚群的分子表达特征,我们可以筛选各个细胞亚群上调表达的基因。
采用Seurat的秩和检验分别对不同类细胞群进行基因差异表达分析,筛选亚群上调表达的基因。
上调基因的筛选条件为:
- 目标亚群或对照亚群中,基因在25%以上的细胞中有表达。
- P值 ≤0.01;
- 基因表达倍数log2FC≥0.36,即基因上调的倍数≥1.28。
| Cluster | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Number of DE genes | 478 | 1423 | 530 | 466 | 584 | 630 | 686 | 944 | 408 | 682 | 811 | 654 | 496 | 661 | 677 | 1660 | 929 | 539 | 345 | 1256 | 529 | 422 | 257 |
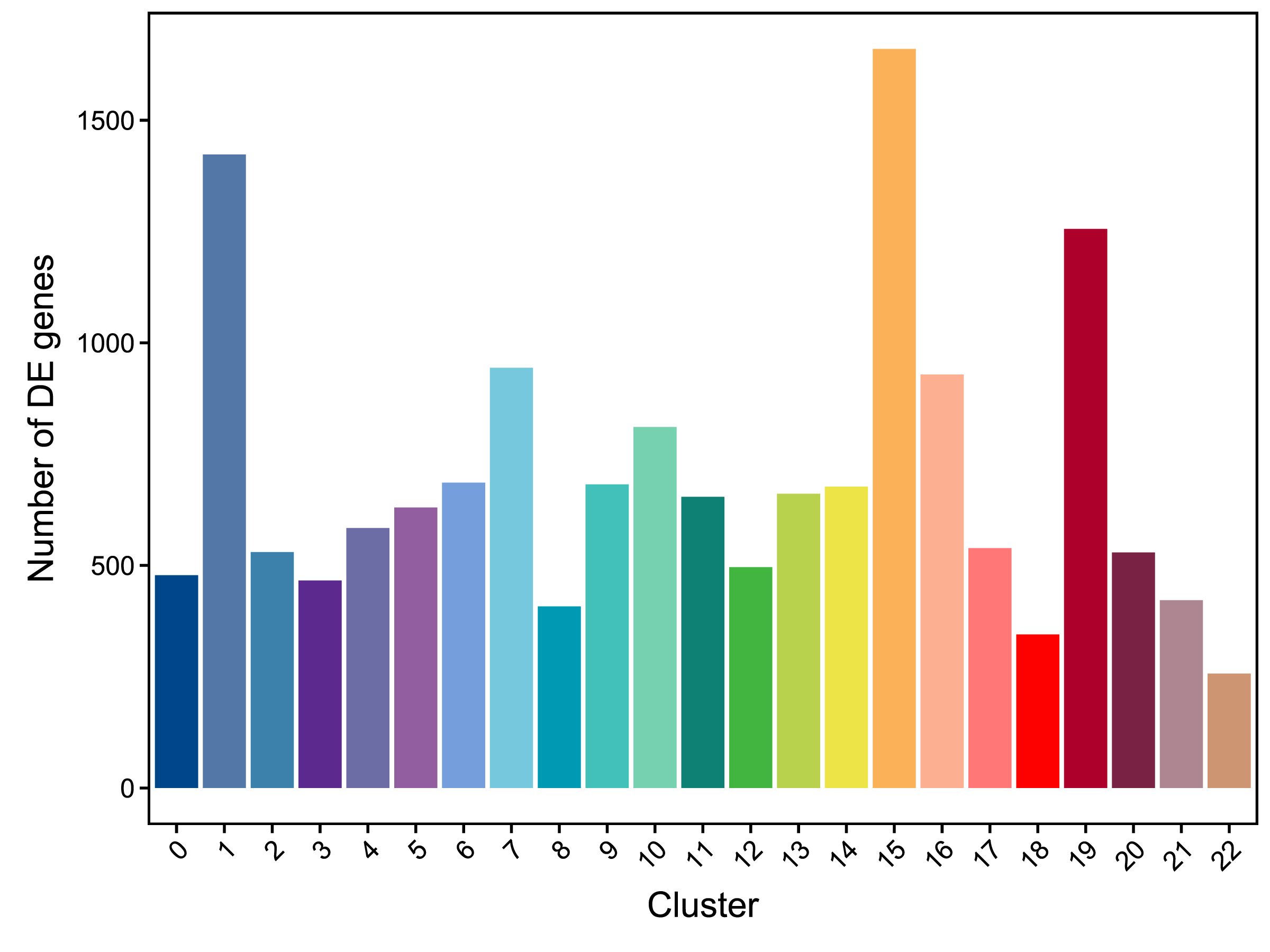 |
| Fig 5-1-1 各亚群上调基因数量统计柱状图 |
各亚群差异基因注释表: 3.MarkerGene/DeGene.list.xls
| Target_Cluster | Gene ID | Gene Name | Target_Cluster_mean | Other_Cluster_mean | Log2FC | Pvalue | Qvalue | Description | KEGG_A_class | KEGG_B_class | Pathway | K_ID | GO Component | GO Function | GO Process |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ENSMUSG00000059657 | Stfa2l1 | 8.88942580026276 | 0.105756270635962 | 6.39327512013097 | 0 | 0 | stefin A2 like 1 [Source:MGI Symbol;Acc:MGI:3524944] | - | - | - | - | GO:0005829//cytosol | GO:0004866//endopeptidase inhibitor activity;GO:0004869//cysteine-type endopeptidase inhibitor activity | GO:0010951//negative regulation of endopeptidase activity |
| 0 | ENSMUSG00000079597 | Cstdc4 | 8.89890190581769 | 0.11556523537951 | 6.26684795028966 | 0 | 0 | cystatin domain containing 4 [Source:MGI Symbol;Acc:MGI:3645124] | - | - | - | - | GO:0001533//cornified envelope;GO:0005615//extracellular space;GO:0005654//nucleoplasm;GO:0005737//cytoplasm;GO:0005829//cytosol | GO:0002020//protease binding;GO:0004866//endopeptidase inhibitor activity;GO:0004869//cysteine-type endopeptidase inhibitor activity | GO:0010951//negative regulation of endopeptidase activity |
| 0 | ENSMUSG00000044103 | Il1f9 | 3.50696143630998 | 0.0488688044740189 | 6.16516394517004 | 0 | 0 | interleukin 1 family, member 9 [Source:MGI Symbol;Acc:MGI:2449929] | Environmental Information Processing | Signaling molecules and interaction | ko04060//Cytokine-cytokine receptor interaction | K05487 | GO:0005576//extracellular region;GO:0005615//extracellular space | GO:0005125//cytokine activity | GO:0006954//inflammatory response;GO:0006955//immune response;GO:0007165//signal transduction |
| 0 | ENSMUSG00000026073 | Il1r2 | 16.7712031319236 | 0.25709751585188 | 6.02752670787483 | 0 | 0 | interleukin 1 receptor, type II [Source:MGI Symbol;Acc:MGI:96546] | Human Diseases;Environmental Information Processing;Human Diseases;Human Diseases;Organismal Systems;Human Diseases;Human Diseases | Cancers;Signaling molecules and interaction;Infectious diseases;Infectious diseases;Immune system;Cardiovascular diseases;Cancers | ko05202//Transcriptional misregulation in cancers;ko04060//Cytokine-cytokine receptor interaction;ko05166//HTLV-I infection;ko05146//Amoebiasis;ko04640//Hematopoietic cell lineage;ko05418//Fluid shear stress and atherosclerosis;ko05215//Prostate cancer | K04387;K04387;K04387;K04387;K04387;K04387;K04387 | GO:0005576//extracellular region;GO:0005737//cytoplasm;GO:0005886//plasma membrane;GO:0016020//membrane;GO:0016021//integral component of membrane | GO:0004908//interleukin-1 receptor activity;GO:0004910//interleukin-1, type II, blocking receptor activity;GO:0019966//interleukin-1 binding | GO:0010955//negative regulation of protein processing;GO:0019221//cytokine-mediated signaling pathway;GO:0032690//negative regulation of interleukin-1 alpha production;GO:1900016//negative regulation of cytokine production involved in inflammatory response;GO:2000660//negative regulation of interleukin-1-mediated signaling pathway |
| 0 | ENSMUSG00000096719 | Mrgpra2b | 3.2371240131999 | 0.0499908836903992 | 6.01690379576071 | 0 | 0 | MAS-related GPR, member A2B [Source:MGI Symbol;Acc:MGI:3033098] | - | - | - | - | GO:0016020//membrane;GO:0016021//integral component of membrane | GO:0004930//G protein-coupled receptor activity | GO:0007186//G protein-coupled receptor signaling pathway |
| 0 | ENSMUSG00000009633 | G0s2 | 213.243397368249 | 3.32029174556802 | 6.00504724892689 | 0 | 0 | G0/G1 switch gene 2 [Source:MGI Symbol;Acc:MGI:1316737] | - | - | - | - | GO:0005739//mitochondrion;GO:0016020//membrane;GO:0016021//integral component of membrane | - | GO:0006915//apoptotic process;GO:0097191//extrinsic apoptotic signaling pathway;GO:0120162//positive regulation of cold-induced thermogenesis;GO:2001238//positive regulation of extrinsic apoptotic signaling pathway |
| 0 | ENSMUSG00000033508 | Asprv1 | 7.95056073767836 | 0.1276160627571 | 5.96117477993645 | 0 | 0 | aspartic peptidase, retroviral-like 1 [Source:MGI Symbol;Acc:MGI:1915105] | - | - | - | - | GO:0016020//membrane;GO:0016021//integral component of membrane | GO:0004190//aspartic-type endopeptidase activity;GO:0008233//peptidase activity;GO:0016787//hydrolase activity | GO:0006508//proteolysis;GO:0016485//protein processing;GO:0043588//skin development |
| 0 | ENSMUSG00000037095 | Lrg1 | 7.75114719016832 | 0.124816438383735 | 5.95652999340728 | 0 | 0 | leucine-rich alpha-2-glycoprotein 1 [Source:MGI Symbol;Acc:MGI:1924155] | - | - | - | - | GO:0005615//extracellular space;GO:0043231//intracellular membrane-bounded organelle | GO:0005160//transforming growth factor beta receptor binding;GO:0005515//protein binding | GO:0001938//positive regulation of endothelial cell proliferation;GO:0009617//response to bacterium;GO:0030511//positive regulation of transforming growth factor beta receptor signaling pathway;GO:0045766//positive regulation of angiogenesis;GO:0050873//brown fat cell differentiation |
| 0 | ENSMUSG00000022126 | Acod1 | 19.0352878203534 | 0.31923461247081 | 5.8979154921034 | 0 | 0 | aconitate decarboxylase 1 [Source:MGI Symbol;Acc:MGI:103206] | Metabolism;Metabolism | Global and overview maps;Carbohydrate metabolism | ko01100//Metabolic pathways;ko00660//C5-Branched dibasic acid metabolism | K17724;K17724 | - | GO:0016829//lyase activity;GO:0047613//aconitate decarboxylase activity | GO:0002760//positive regulation of antimicrobial humoral response;GO:0006952//defense response;GO:0071222//cellular response to lipopolysaccharide;GO:0072573//tolerance induction to lipopolysaccharide |
| 0 | ENSMUSG00000035692 | Isg15 | 8.38876469222025 | 0.141955149739123 | 5.88495128666847 | 0 | 0 | ISG15 ubiquitin-like modifier [Source:MGI Symbol;Acc:MGI:1855694] | Human Diseases;Human Diseases;Organismal Systems | Infectious diseases;Infectious diseases;Immune system | ko05169//Epstein-Barr virus infection;ko05165//Human papillomavirus infection;ko04622//RIG-I-like receptor signaling pathway | K12159;K12159;K12159 | GO:0005576//extracellular region;GO:0005634//nucleus;GO:0005737//cytoplasm;GO:0022627//cytosolic small ribosomal subunit | GO:0005178//integrin binding;GO:0005515//protein binding;GO:0031386//protein tag;GO:0031625//ubiquitin protein ligase binding | GO:0007229//integrin-mediated signaling pathway;GO:0009615//response to virus;GO:0009617//response to bacterium;GO:0019941//modification-dependent protein catabolic process;GO:0030501//positive regulation of bone mineralization;GO:0031397//negative regulation of protein ubiquitination;GO:0032020//ISG15-protein conjugation;GO:0032649//regulation of interferon-gamma production;GO:0032729//positive regulation of interferon-gamma production;GO:0032733//positive regulation of interleukin-10 production;GO:0034340//response to type I interferon;GO:0042742//defense response to bacterium;GO:0045071//negative regulation of viral genome replication;GO:0045648//positive regulation of erythrocyte differentiation;GO:0051607//defense response to virus;GO:0060339//negative regulation of type I interferon-mediated signaling pathway |
| 0 | ENSMUSG00000056071 | S100a9 | 711.733000040033 | 13.2198243478743 | 5.75056121620592 | 0 | 0 | S100 calcium binding protein A9 (calgranulin B) [Source:MGI Symbol;Acc:MGI:1338947] | Organismal Systems | Immune system | ko04657//IL-17 signaling pathway | K21128 | GO:0005576//extracellular region;GO:0005615//extracellular space;GO:0005634//nucleus;GO:0005654//nucleoplasm;GO:0005737//cytoplasm;GO:0005829//cytosol;GO:0005856//cytoskeleton;GO:0005886//plasma membrane;GO:0016020//membrane;GO:0030054//cell junction | GO:0005509//calcium ion binding;GO:0016209//antioxidant activity;GO:0046872//metal ion binding;GO:0048306//calcium-dependent protein binding | GO:0002376//immune system process;GO:0002523//leukocyte migration involved in inflammatory response;GO:0002544//chronic inflammatory response;GO:0002793//positive regulation of peptide secretion;GO:0006417//regulation of translation;GO:0006914//autophagy;GO:0006915//apoptotic process;GO:0006919//activation of cysteine-type endopeptidase activity involved in apoptotic process;GO:0006935//chemotaxis;GO:0006954//inflammatory response;GO:0010976//positive regulation of neuron projection development;GO:0014002//astrocyte development;GO:0018119//peptidyl-cysteine S-nitrosylation;GO:0030194//positive regulation of blood coagulation;GO:0030593//neutrophil chemotaxis;GO:0030595//leukocyte chemotaxis;GO:0031532//actin cytoskeleton reorganization;GO:0032496//response to lipopolysaccharide;GO:0035425//autocrine signaling;GO:0035606//peptidyl-cysteine S-trans-nitrosylation;GO:0035821//modification of morphology or physiology of other organism;GO:0045087//innate immune response;GO:0045113//regulation of integrin biosynthetic process;GO:0050729//positive regulation of inflammatory response;GO:0061844//antimicrobial humoral immune response mediated by antimicrobial peptide;GO:0070488//neutrophil aggregation;GO:0098869//cellular oxidant detoxification;GO:2001244//positive regulation of intrinsic apoptotic signaling pathway |
| 0 | ENSMUSG00000042265 | Trem1 | 18.8367153731058 | 0.356775544229531 | 5.72238688192314 | 0 | 0 | triggering receptor expressed on myeloid cells 1 [Source:MGI Symbol;Acc:MGI:1930005] | - | - | - | - | GO:0005886//plasma membrane;GO:0016020//membrane;GO:0016021//integral component of membrane | GO:0038023//signaling receptor activity;GO:0097110//scaffold protein binding | GO:0002250//adaptive immune response;GO:0002376//immune system process;GO:0002526//acute inflammatory response;GO:0016477//cell migration;GO:0030593//neutrophil chemotaxis;GO:0045087//innate immune response;GO:0070945//neutrophil mediated killing of gram-negative bacterium;GO:0072672//neutrophil extravasation |
| 0 | ENSMUSG00000027398 | Il1b | 365.658542786149 | 6.95624655195386 | 5.71604419016099 | 0 | 0 | interleukin 1 beta [Source:MGI Symbol;Acc:MGI:96543] | Human Diseases;Human Diseases;Human Diseases;Environmental Information Processing;Human Diseases;Environmental Information Processing;Environmental Information Processing;Human Diseases;Human Diseases;Human Diseases;Human Diseases;Human Diseases;Organismal Systems;Organismal Systems;Human Diseases;Human Diseases;Human Diseases;Cellular Processes;Human Diseases;Human Diseases;Human Diseases;Human Diseases;Human Diseases;Organismal Systems;Organismal Systems;Organismal Systems;Environmental Information Processing;Organismal Systems;Human Diseases;Human Diseases;Human Diseases;Organismal Systems;Organismal Systems;Human Diseases;Human Diseases;Human Diseases;Organismal Systems;Human Diseases;Human Diseases;Human Diseases | Infectious diseases;Infectious diseases;Neurodegenerative diseases;Signaling molecules and interaction;Infectious diseases;Signal transduction;Signal transduction;Immune diseases;Infectious diseases;Infectious diseases;Infectious diseases;Infectious diseases;Immune system;Immune system;Infectious diseases;Infectious diseases;Infectious diseases;Cell growth and death;Infectious disease: bacterial;Infectious diseases;Cardiovascular diseases;Endocrine and metabolic diseases;Infectious diseases;Immune system;Sensory system;Development;Signal transduction;Immune system;Endocrine and metabolic diseases;Immune diseases;Endocrine and metabolic diseases;Immune system;Immune system;Infectious diseases;Immune diseases;Infectious diseases;Immune system;Infectious diseases;Neurodegenerative diseases;Drug resistance | ko05168//Herpes simplex infection;ko05130//Pathogenic Escherichia coli infection;ko05010//Alzheimer disease;ko04060//Cytokine-cytokine receptor interaction;ko05152//Tuberculosis;ko04010//MAPK signaling pathway;ko04064//NF-kappa B signaling pathway;ko05323//Rheumatoid arthritis;ko05163//Human cytomegalovirus infection;ko05131//Shigellosis;ko05146//Amoebiasis;ko05132//Salmonella infection;ko04621//NOD-like receptor signaling pathway;ko04640//Hematopoietic cell lineage;ko05162//Measles;ko05140//Leishmaniasis;ko05164//Influenza A;ko04217//Necroptosis;ko05135//Yersinia infection;ko05143//African trypanosomiasis;ko05418//Fluid shear stress and atherosclerosis;ko04932//Non-alcoholic fatty liver disease (NAFLD);ko05142//Chagas disease (American trypanosomiasis);ko04659//Th17 cell differentiation;ko04750//Inflammatory mediator regulation of TRP channels;ko04380//Osteoclast differentiation;ko04668//TNF signaling pathway;ko04625//C-type lectin receptor signaling pathway;ko04940//Type I diabetes mellitus;ko05321//Inflammatiory bowel disease (IBD);ko04933//AGE-RAGE signaling pathway in diabetic complications;ko04620//Toll-like receptor signaling pathway;ko04657//IL-17 signaling pathway;ko05144//Malaria;ko05332//Graft-versus-host disease;ko05133//Pertussis;ko04623//Cytosolic DNA-sensing pathway;ko05134//Legionellosis;ko05020//Prion diseases;ko01523//Antifolate resistance | K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519;K04519 | GO:0005576//extracellular region;GO:0005615//extracellular space;GO:0005737//cytoplasm;GO:0005764//lysosome;GO:0005776//autophagosome;GO:0005829//cytosol;GO:0030141//secretory granule;GO:0031410//cytoplasmic vesicle;GO:0031982//vesicle | GO:0005125//cytokine activity;GO:0005149//interleukin-1 receptor binding;GO:0005178//integrin binding;GO:0019904//protein domain specific binding | GO:0000122//negative regulation of transcription by RNA polymerase II;GO:0000165//MAPK cascade;GO:0000187//activation of MAPK activity;GO:0001660//fever generation;GO:0001934//positive regulation of protein phosphorylation;GO:0006954//inflammatory response;GO:0006955//immune response;GO:0007204//positive regulation of cytosolic calcium ion concentration;GO:0007613//memory;GO:0008284//positive regulation of cell proliferation;GO:0008285//negative regulation of cell proliferation;GO:0009743//response to carbohydrate;GO:0010573//vascular endothelial growth factor production;GO:0010575//positive regulation of vascular endothelial growth factor production;GO:0010628//positive regulation of gene expression;GO:0010629//negative regulation of gene expression;GO:0010718//positive regulation of epithelial to mesenchymal transition;GO:0010829//negative regulation of glucose transmembrane transport;GO:0010942//positive regulation of cell death;GO:0014050//negative regulation of glutamate secretion;GO:0019221//cytokine-mediated signaling pathway;GO:0030213//hyaluronan biosynthetic process;GO:0030335//positive regulation of cell migration;GO:0030593//neutrophil chemotaxis;GO:0030730//sequestering of triglyceride;GO:0031394//positive regulation of prostaglandin biosynthetic process;GO:0031622//positive regulation of fever generation;GO:0031663//lipopolysaccharide-mediated signaling pathway;GO:0032308//positive regulation of prostaglandin secretion;GO:0032496//response to lipopolysaccharide;GO:0032722//positive regulation of chemokine production;GO:0032725//positive regulation of granulocyte macrophage colony-stimulating factor production;GO:0032729//positive regulation of interferon-gamma production;GO:0032743//positive regulation of interleukin-2 production;GO:0032755//positive regulation of interleukin-6 production;GO:0032757//positive regulation of interleukin-8 production;GO:0032874//positive regulation of stress-activated MAPK cascade;GO:0033092//positive regulation of immature T cell proliferation in thymus;GO:0033198//response to ATP;GO:0034116//positive regulation of heterotypic cell-cell adhesion;GO:0035176//social behavior;GO:0035234//ectopic germ cell programmed cell death;GO:0035505//positive regulation of myosin light chain kinase activity;GO:0035690//cellular response to drug;GO:0042102//positive regulation of T cell proliferation;GO:0043065//positive regulation of apoptotic process;GO:0043122//regulation of I-kappaB kinase/NF-kappaB signaling;GO:0043123//positive regulation of I-kappaB kinase/NF-kappaB signaling;GO:0043407//negative regulation of MAP kinase activity;GO:0043491//protein kinase B signaling;GO:0043507//positive regulation of JUN kinase activity;GO:0043525//positive regulation of neuron apoptotic process;GO:0045429//positive regulation of nitric oxide biosynthetic process;GO:0045665//negative regulation of neuron differentiation;GO:0045687//positive regulation of glial cell differentiation;GO:0045766//positive regulation of angiogenesis;GO:0045833//negative regulation of lipid metabolic process;GO:0045840//positive regulation of mitotic nuclear division;GO:0045893//positive regulation of transcription, DNA-templated;GO:0045917//positive regulation of complement activation;GO:0045944//positive regulation of transcription by RNA polymerase II;GO:0046330//positive regulation of JNK cascade;GO:0046627//negative regulation of insulin receptor signaling pathway;GO:0048143//astrocyte activation;GO:0048711//positive regulation of astrocyte differentiation;GO:0050691//regulation of defense response to virus by host;GO:0050729//positive regulation of inflammatory response;GO:0050766//positive regulation of phagocytosis;GO:0050767//regulation of neurogenesis;GO:0050768//negative regulation of neurogenesis;GO:0050796//regulation of insulin secretion;GO:0050805//negative regulation of synaptic transmission;GO:0050900//leukocyte migration;GO:0050995//negative regulation of lipid catabolic process;GO:0050996//positive regulation of lipid catabolic process;GO:0050999//regulation of nitric-oxide synthase activity;GO:0051044//positive regulation of membrane protein ectodomain proteolysis;GO:0051091//positive regulation of DNA-binding transcription factor activity;GO:0051092//positive regulation of NF-kappaB transcription factor activity;GO:0051781//positive regulation of cell division;GO:0060252//positive regulation of glial cell proliferation;GO:0060559//positive regulation of calcidiol 1-monooxygenase activity;GO:0070164//negative regulation of adiponectin secretion;GO:0070372//regulation of ERK1 and ERK2 cascade;GO:0070374//positive regulation of ERK1 and ERK2 cascade;GO:0070487//monocyte aggregation;GO:0070498//interleukin-1-mediated signaling pathway;GO:0070555//response to interleukin-1;GO:0071222//cellular response to lipopolysaccharide;GO:0071310//cellular response to organic substance;GO:0071407//cellular response to organic cyclic compound;GO:0071639//positive regulation of monocyte chemotactic protein-1 production;GO:0090023//positive regulation of neutrophil chemotaxis;GO:0097192//extrinsic apoptotic signaling pathway in absence of ligand;GO:1900745//positive regulation of p38MAPK cascade;GO:1901224//positive regulation of NIK/NF-kappaB signaling;GO:1902680//positive regulation of RNA biosynthetic process;GO:1903140//regulation of establishment of endothelial barrier;GO:1903597//negative regulation of gap junction assembly;GO:2000173//negative regulation of branching morphogenesis of a nerve;GO:2000178//negative regulation of neural precursor cell proliferation;GO:2000556//positive regulation of T-helper 1 cell cytokine production;GO:2001240//negative regulation of extrinsic apoptotic signaling pathway in absence of ligand |
| 0 | ENSMUSG00000032487 | Ptgs2 | 24.66064123401 | 0.48496885474809 | 5.66817440467171 | 0 | 0 | prostaglandin-endoperoxide synthase 2 [Source:MGI Symbol;Acc:MGI:97798] | Metabolism;Human Diseases;Human Diseases;Human Diseases;Environmental Information Processing;Human Diseases;Human Diseases;Human Diseases;Human Diseases;Organismal Systems;Organismal Systems;Organismal Systems;Environmental Information Processing;Organismal Systems;Human Diseases;Organismal Systems;Human Diseases;Metabolism;Organismal Systems;Environmental Information Processing;Organismal Systems | Global and overview maps;Cancers;Infectious diseases;Neurodegenerative diseases;Signal transduction;Infectious diseases;Infectious diseases;Infectious diseases;Cancers;Endocrine system;Nervous system;Nervous system;Signal transduction;Immune system;Cancers;Immune system;Cancers;Lipid metabolism;Endocrine system;Signal transduction;Endocrine system | ko01100//Metabolic pathways;ko05200//Pathways in cancer;ko05165//Human papillomavirus infection;ko05010//Alzheimer disease;ko04064//NF-kappa B signaling pathway;ko05163//Human cytomegalovirus infection;ko05167//Kaposi sarcoma-associated herpesvirus infection;ko05140//Leishmaniasis;ko05206//MicroRNAs in cancer;ko04921//Oxytocin signaling pathway;ko04723//Retrograde endocannabinoid signaling;ko04726//Serotonergic synapse;ko04668//TNF signaling pathway;ko04625//C-type lectin receptor signaling pathway;ko05204//Chemical carcinogenesis;ko04657//IL-17 signaling pathway;ko05222//Small cell lung cancer;ko00590//Arachidonic acid metabolism;ko04913//Ovarian Steroidogenesis;ko04370//VEGF signaling pathway;ko04923//Regulation of lipolysis in adipocyte | K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987;K11987 | GO:0005634//nucleus;GO:0005637//nuclear inner membrane;GO:0005640//nuclear outer membrane;GO:0005737//cytoplasm;GO:0005783//endoplasmic reticulum;GO:0005789//endoplasmic reticulum membrane;GO:0005901//caveola;GO:0016020//membrane;GO:0032991//protein-containing complex;GO:0043005//neuron projection;GO:0043231//intracellular membrane-bounded organelle | GO:0004601//peroxidase activity;GO:0004666//prostaglandin-endoperoxide synthase activity;GO:0005515//protein binding;GO:0016491//oxidoreductase activity;GO:0016702//oxidoreductase activity, acting on single donors with incorporation of molecular oxygen, incorporation of two atoms of oxygen;GO:0019899//enzyme binding;GO:0020037//heme binding;GO:0042803//protein homodimerization activity;GO:0046872//metal ion binding;GO:0051213//dioxygenase activity | GO:0001516//prostaglandin biosynthetic process;GO:0001525//angiogenesis;GO:0006629//lipid metabolic process;GO:0006631//fatty acid metabolic process;GO:0006633//fatty acid biosynthetic process;GO:0006693//prostaglandin metabolic process;GO:0006954//inflammatory response;GO:0006979//response to oxidative stress;GO:0007566//embryo implantation;GO:0007568//aging;GO:0007612//learning;GO:0007613//memory;GO:0008217//regulation of blood pressure;GO:0008284//positive regulation of cell proliferation;GO:0008285//negative regulation of cell proliferation;GO:0009314//response to radiation;GO:0009750//response to fructose;GO:0010033//response to organic substance;GO:0010042//response to manganese ion;GO:0010226//response to lithium ion;GO:0010243//response to organonitrogen compound;GO:0010575//positive regulation of vascular endothelial growth factor production;GO:0010942//positive regulation of cell death;GO:0014070//response to organic cyclic compound;GO:0019233//sensory perception of pain;GO:0019371//cyclooxygenase pathway;GO:0030216//keratinocyte differentiation;GO:0030282//bone mineralization;GO:0030728//ovulation;GO:0031394//positive regulation of prostaglandin biosynthetic process;GO:0031622//positive regulation of fever generation;GO:0031915//positive regulation of synaptic plasticity;GO:0032227//negative regulation of synaptic transmission, dopaminergic;GO:0032355//response to estradiol;GO:0032496//response to lipopolysaccharide;GO:0033138//positive regulation of peptidyl-serine phosphorylation;GO:0033280//response to vitamin D;GO:0034097//response to cytokine;GO:0034605//cellular response to heat;GO:0034612//response to tumor necrosis factor;GO:0034644//cellular response to UV;GO:0035633//maintenance of permeability of blood-brain barrier;GO:0042127//regulation of cell proliferation;GO:0042307//positive regulation of protein import into nucleus;GO:0042493//response to drug;GO:0042633//hair cycle;GO:0043065//positive regulation of apoptotic process;GO:0043066//negative regulation of apoptotic process;GO:0043154//negative regulation of cysteine-type endopeptidase activity involved in apoptotic process;GO:0045429//positive regulation of nitric oxide biosynthetic process;GO:0045786//negative regulation of cell cycle;GO:0045907//positive regulation of vasoconstriction;GO:0045986//negative regulation of smooth muscle contraction;GO:0045987//positive regulation of smooth muscle contraction;GO:0046697//decidualization;GO:0048661//positive regulation of smooth muscle cell proliferation;GO:0050873//brown fat cell differentiation;GO:0051384//response to glucocorticoid;GO:0051926//negative regulation of calcium ion transport;GO:0051968//positive regulation of synaptic transmission, glutamatergic;GO:0055114//oxidation-reduction process;GO:0070542//response to fatty acid;GO:0071260//cellular response to mechanical stimulus;GO:0071284//cellular response to lead ion;GO:0071318//cellular response to ATP;GO:0071456//cellular response to hypoxia;GO:0071471//cellular response to non-ionic osmotic stress;GO:0071498//cellular response to fluid shear stress;GO:0071636//positive regulation of transforming growth factor beta production;GO:0090050//positive regulation of cell migration involved in sprouting angiogenesis;GO:0090271//positive regulation of fibroblast growth factor production;GO:0090336//positive regulation of brown fat cell differentiation;GO:0090362//positive regulation of platelet-derived growth factor production;GO:0098869//cellular oxidant detoxification;GO:0150077//regulation of neuroinflammatory response;GO:1902219//negative regulation of intrinsic apoptotic signaling pathway in response to osmotic stress;GO:1990776//response to angiotensin |
| 0 | ENSMUSG00000026180 | Cxcr2 | 11.5527366739328 | 0.227200597863935 | 5.66812420399522 | 0 | 0 | chemokine (C-X-C motif) receptor 2 [Source:MGI Symbol;Acc:MGI:105303] | Environmental Information Processing;Environmental Information Processing;Cellular Processes;Human Diseases;Organismal Systems;Environmental Information Processing;Human Diseases | Signaling molecules and interaction;Signal transduction;Transport and catabolism;Infectious diseases;Immune system;Signaling molecules and interaction;Infectious diseases | ko04060//Cytokine-cytokine receptor interaction;ko04072//Phospholipase D signaling pathway;ko04144//Endocytosis;ko05163//Human cytomegalovirus infection;ko04062//Chemokine signaling pathway;ko04061//Viral protein interaction with cytokine and cytokine receptor;ko05120//Epithelial cell signaling in Helicobacter pylori infection | K05050;K05050;K05050;K05050;K05050;K05050;K05050 | GO:0005654//nucleoplasm;GO:0005886//plasma membrane;GO:0009897//external side of plasma membrane;GO:0009986//cell surface;GO:0015630//microtubule cytoskeleton;GO:0016020//membrane;GO:0016021//integral component of membrane;GO:0042629//mast cell granule;GO:0072686//mitotic spindle | GO:0004918//interleukin-8 receptor activity;GO:0004930//G protein-coupled receptor activity;GO:0004950//chemokine receptor activity;GO:0005515//protein binding;GO:0016493//C-C chemokine receptor activity;GO:0016494//C-X-C chemokine receptor activity;GO:0019957//C-C chemokine binding;GO:0019959//interleukin-8 binding | GO:0002438//acute inflammatory response to antigenic stimulus;GO:0002690//positive regulation of leukocyte chemotaxis;GO:0006935//chemotaxis;GO:0006955//immune response;GO:0006968//cellular defense response;GO:0007165//signal transduction;GO:0007166//cell surface receptor signaling pathway;GO:0007186//G protein-coupled receptor signaling pathway;GO:0007200//phospholipase C-activating G protein-coupled receptor signaling pathway;GO:0007204//positive regulation of cytosolic calcium ion concentration;GO:0008284//positive regulation of cell proliferation;GO:0010666//positive regulation of cardiac muscle cell apoptotic process;GO:0019722//calcium-mediated signaling;GO:0030593//neutrophil chemotaxis;GO:0030901//midbrain development;GO:0031623//receptor internalization;GO:0033030//negative regulation of neutrophil apoptotic process;GO:0038112//interleukin-8-mediated signaling pathway;GO:0042119//neutrophil activation;GO:0043066//negative regulation of apoptotic process;GO:0043117//positive regulation of vascular permeability;GO:0045766//positive regulation of angiogenesis;GO:0060326//cell chemotaxis;GO:0070098//chemokine-mediated signaling pathway;GO:0072173//metanephric tubule morphogenesis;GO:0090023//positive regulation of neutrophil chemotaxis |
| 0 | ENSMUSG00000041754 | Trem3 | 4.23600274916225 | 0.0857123310326993 | 5.62705694234742 | 0 | 0 | triggering receptor expressed on myeloid cells 3 [Source:MGI Symbol;Acc:MGI:1930003] | - | - | - | - | GO:0005886//plasma membrane;GO:0016020//membrane;GO:0016021//integral component of membrane | GO:0005515//protein binding | GO:0016477//cell migration;GO:0030593//neutrophil chemotaxis;GO:0045089//positive regulation of innate immune response;GO:0070945//neutrophil mediated killing of gram-negative bacterium;GO:0072672//neutrophil extravasation |
| 0 | ENSMUSG00000022237 | Ankrd33b | 5.95321388563449 | 0.126979847598432 | 5.55099727147334 | 0 | 0 | ankyrin repeat domain 33B [Source:MGI Symbol;Acc:MGI:1917904] | - | - | - | - | GO:0005575//cellular_component | GO:0003674//molecular_function;GO:0003677//DNA binding;GO:0005515//protein binding | GO:0008150//biological_process |
| 0 | ENSMUSG00000056054 | S100a8 | 296.744259898683 | 6.55885620905299 | 5.49963206605389 | 0 | 0 | S100 calcium binding protein A8 (calgranulin A) [Source:MGI Symbol;Acc:MGI:88244] | Organismal Systems | Immune system | ko04657//IL-17 signaling pathway | K21127 | GO:0005576//extracellular region;GO:0005615//extracellular space;GO:0005737//cytoplasm;GO:0005829//cytosol;GO:0005856//cytoskeleton;GO:0005886//plasma membrane;GO:0016020//membrane;GO:0045111//intermediate filament cytoskeleton | GO:0005509//calcium ion binding;GO:0008017//microtubule binding;GO:0008270//zinc ion binding;GO:0016209//antioxidant activity;GO:0035662//Toll-like receptor 4 binding;GO:0046872//metal ion binding;GO:0048306//calcium-dependent protein binding;GO:0050544//arachidonic acid binding;GO:0050786//RAGE receptor binding | GO:0002376//immune system process;GO:0002523//leukocyte migration involved in inflammatory response;GO:0002793//positive regulation of peptide secretion;GO:0006914//autophagy;GO:0006915//apoptotic process;GO:0006919//activation of cysteine-type endopeptidase activity involved in apoptotic process;GO:0006935//chemotaxis;GO:0006954//inflammatory response;GO:0014002//astrocyte development;GO:0018119//peptidyl-cysteine S-nitrosylation;GO:0030593//neutrophil chemotaxis;GO:0032496//response to lipopolysaccharide;GO:0035425//autocrine signaling;GO:0045087//innate immune response;GO:0050727//regulation of inflammatory response;GO:0050729//positive regulation of inflammatory response;GO:0070488//neutrophil aggregation;GO:0098869//cellular oxidant detoxification;GO:2001244//positive regulation of intrinsic apoptotic signaling pathway |
| 0 | ENSMUSG00000028859 | Csf3r | 22.1423079802541 | 0.501026150234955 | 5.46577589305894 | 0 | 0 | colony stimulating factor 3 receptor (granulocyte) [Source:MGI Symbol;Acc:MGI:1339755] | Human Diseases;Environmental Information Processing;Environmental Information Processing;Organismal Systems;Environmental Information Processing | Cancers;Signal transduction;Signaling molecules and interaction;Immune system;Signal transduction | ko05200//Pathways in cancer;ko04151//PI3K-Akt signaling pathway;ko04060//Cytokine-cytokine receptor interaction;ko04640//Hematopoietic cell lineage;ko04630//Jak-STAT signaling pathway | K05061;K05061;K05061;K05061;K05061 | GO:0005886//plasma membrane;GO:0009897//external side of plasma membrane;GO:0016020//membrane;GO:0016021//integral component of membrane;GO:0043235//receptor complex | GO:0004896//cytokine receptor activity;GO:0005515//protein binding;GO:0019955//cytokine binding;GO:0051916//granulocyte colony-stimulating factor binding | GO:0007155//cell adhesion;GO:0019221//cytokine-mediated signaling pathway;GO:0030593//neutrophil chemotaxis;GO:0045637//regulation of myeloid cell differentiation;GO:0097186//amelogenesis |
| 0 | ENSMUSG00000027068 | Dhrs9 | 2.5765119925528 | 0.0598470150634583 | 5.42799620446395 | 0 | 0 | dehydrogenase/reductase (SDR family) member 9 [Source:MGI Symbol;Acc:MGI:2442798] | Metabolism;Metabolism | Global and overview maps;Metabolism of cofactors and vitamins | ko01100//Metabolic pathways;ko00830//Retinol metabolism | K11149;K11149 | GO:0005783//endoplasmic reticulum;GO:0005789//endoplasmic reticulum membrane;GO:0016020//membrane;GO:0030176//integral component of endoplasmic reticulum membrane;GO:0043231//intracellular membrane-bounded organelle | GO:0004022//alcohol dehydrogenase (NAD) activity;GO:0004745//retinol dehydrogenase activity;GO:0016491//oxidoreductase activity;GO:0047023//androsterone dehydrogenase activity;GO:0047035//testosterone dehydrogenase (NAD+) activity;GO:0047044//androstan-3-alpha,17-beta-diol dehydrogenase activity | GO:0002138//retinoic acid biosynthetic process;GO:0006629//lipid metabolic process;GO:0008202//steroid metabolic process;GO:0008209//androgen metabolic process;GO:0042448//progesterone metabolic process;GO:0042904//9-cis-retinoic acid biosynthetic process;GO:0055114//oxidation-reduction process |
5.2 上调基因表达分布
图形是比表格更优秀的数据呈现形式。我们使用热图、tSNE图、密度分布图、小提琴图和气泡图来可视化基因在细胞和各个细胞亚群的表达分布情况。(选择亚群上调top5的基因用于绘图)
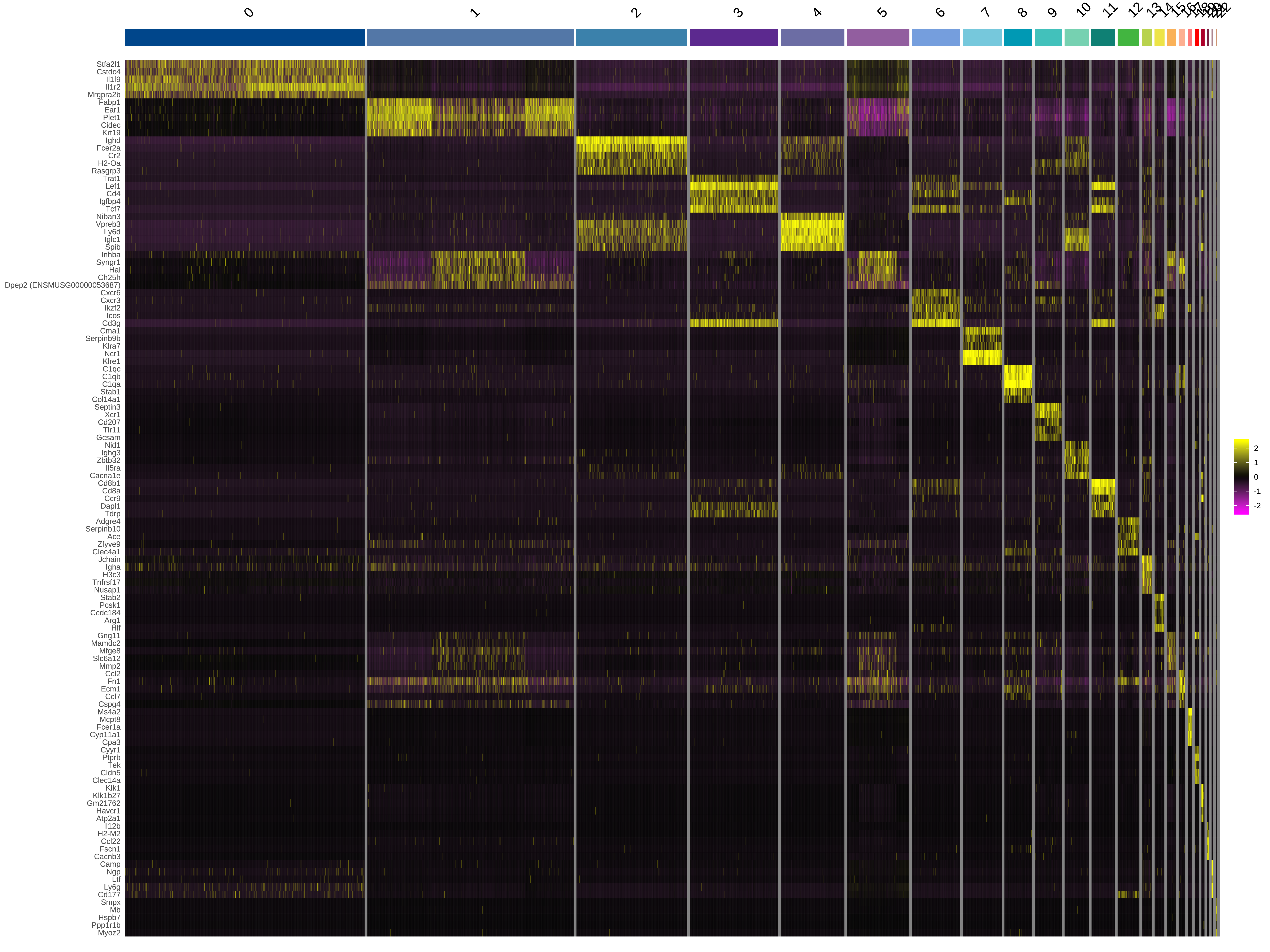 |
| Fig 5-2-1 标记基因表达热图 |
 |
| Fig 5-2-2 标记基因表达分布气泡图 |
上调基因表达分布图只展示其中5个基因,其他top5的基因请浏览文件夹3.MarkerGene/Plots/ExpPlot
- Ace
- Adgre4
- Arg1
- Atp2a1
- C1qa
Fig 5-2-3 标记基因表达分布图
上调基因表达分布密度图只展示其中5个基因,其他top5的基因请浏览文件夹3.MarkerGene/Plots/DensityPlot
- Ace
- Adgre4
- Arg1
- Atp2a1
- C1qa
Fig 5-2-4 标记基因表达分布密度图
上调基因表达分布小提琴图只展示其中5个基因,其他top5的基因请浏览文件夹3.MarkerGene/Plots/ViolinPlot
- Ace
- Adgre4
- Arg1
- Atp2a1
- C1qa
Fig 5-2-5 标记基因表达分布小提琴图
5.3 GO富集分析
Gene Ontology(简称GO)是一个国际标准化的基因功能分类体系,提供了一套动态更新的标准词汇表(controlled vocabulary)来全面描述生物体中基因和基因产物的属性。GO总共有三个ontology(本体),分别描述基因的分子功能(molecular function)、细胞组分(cellular component)、参与的生物过程(biological process)。GO的基本单位是term(词条、节点),每个term都对应一个属性。 GO功能分析一方面给出基因的GO功能分类注释;另一方面给出基因的GO功能显著性富集分析。 首先,我们将基因向GO数据库(http://www.geneontology.org/)的各term映射,并计算每个term的基因数,从而得到具有某个GO功能的基因列表及基因数目统计。然后应用超几何检验,找出与整个基因组背景相比,在基因中显著富集的GO条目。
GO富集圈图:(第一圈:富集前20的GOterm,圈外为基因数目的坐标尺。不同的颜色代表不同的Ontology; 第二圈:背景基因中该GOterm的数目以及Q值。基因越多条形越长,Q值越小颜色越红; 第三圈:该GOterm差异基因数量 第四圈:各GOterm的RichFactor值(该GOterm中差异数量除以所有数量),背景网格线,每一格代表0.1)
- Cluster_0 富集圈图
- Cluster_1 富集圈图
- Cluster_2 富集圈图
- Cluster_3 富集圈图
- Cluster_4 富集圈图
- Cluster_5 富集圈图
- Cluster_6 富集圈图
- Cluster_7 富集圈图
- Cluster_8 富集圈图
- Cluster_9 富集圈图
- Cluster_10 富集圈图
- Cluster_11 富集圈图
- Cluster_12 富集圈图
- Cluster_13 富集圈图
- Cluster_14 富集圈图
- Cluster_15 富集圈图
- Cluster_16 富集圈图
- Cluster_17 富集圈图
- Cluster_18 富集圈图
- Cluster_19 富集圈图
- Cluster_20 富集圈图
- Cluster_21 富集圈图
- Cluster_22 富集圈图
Fig 5-3-1 GO 富集圈图
GO 富集分类柱状图:(横坐标为二级GOterm,纵坐标为该term里的基因数量,不同颜色表色不同类型GOterm)
- Cluster_0
- Cluster_1
- Cluster_2
- Cluster_3
- Cluster_4
- Cluster_5
- Cluster_6
- Cluster_7
- Cluster_8
- Cluster_9
- Cluster_10
- Cluster_11
- Cluster_12
- Cluster_13
- Cluster_14
- Cluster_15
- Cluster_16
- Cluster_17
- Cluster_18
- Cluster_19
- Cluster_20
- Cluster_21
- Cluster_22
Fig 5-3-2 GO富集分类柱状图
GO富集气泡图:(利用Q值最小的前20个GOterm来作图,纵坐标为GOterm,横坐标为富集因子(该GOterm中差异数量除以所有数量),大小表示数量多少,颜色越红Q值越小)");
- Cluster_0.C 气泡图
- Cluster_0.F 气泡图
- Cluster_0.P 气泡图
- Cluster_1.C 气泡图
- Cluster_1.F 气泡图
- Cluster_1.P 气泡图
- Cluster_2.C 气泡图
- Cluster_2.F 气泡图
- Cluster_2.P 气泡图
- Cluster_3.C 气泡图
- Cluster_3.F 气泡图
- Cluster_3.P 气泡图
- Cluster_4.C 气泡图
- Cluster_4.F 气泡图
- Cluster_4.P 气泡图
- Cluster_5.C 气泡图
- Cluster_5.F 气泡图
- Cluster_5.P 气泡图
- Cluster_6.C 气泡图
- Cluster_6.F 气泡图
- Cluster_6.P 气泡图
- Cluster_7.C 气泡图
- Cluster_7.F 气泡图
- Cluster_7.P 气泡图
- Cluster_8.C 气泡图
- Cluster_8.F 气泡图
- Cluster_8.P 气泡图
- Cluster_9.C 气泡图
- Cluster_9.F 气泡图
- Cluster_9.P 气泡图
- Cluster_10.C 气泡图
- Cluster_10.F 气泡图
- Cluster_10.P 气泡图
- Cluster_11.C 气泡图
- Cluster_11.F 气泡图
- Cluster_11.P 气泡图
- Cluster_12.C 气泡图
- Cluster_12.F 气泡图
- Cluster_12.P 气泡图
- Cluster_13.C 气泡图
- Cluster_13.F 气泡图
- Cluster_13.P 气泡图
- Cluster_14.C 气泡图
- Cluster_14.F 气泡图
- Cluster_14.P 气泡图
- Cluster_15.C 气泡图
- Cluster_15.F 气泡图
- Cluster_15.P 气泡图
- Cluster_16.C 气泡图
- Cluster_16.F 气泡图
- Cluster_16.P 气泡图
- Cluster_17.C 气泡图
- Cluster_17.F 气泡图
- Cluster_17.P 气泡图
- Cluster_18.C 气泡图
- Cluster_18.F 气泡图
- Cluster_18.P 气泡图
- Cluster_19.C 气泡图
- Cluster_19.F 气泡图
- Cluster_19.P 气泡图
- Cluster_20.C 气泡图
- Cluster_20.F 气泡图
- Cluster_20.P 气泡图
- Cluster_21.C 气泡图
- Cluster_21.F 气泡图
- Cluster_21.P 气泡图
- Cluster_22.C 气泡图
- Cluster_22.F 气泡图
- Cluster_22.P 气泡图
Fig 5-3-3 GO富集气泡图
GO富集条形图:(利用Q值最小的前20个GOterm来作图,纵坐标为GOterm,横坐标为该GOterm数目占所有差异数目的百分比,颜色越深Q值越小,柱子上的数值为该GOterm数量及Q值");
- Cluster_0.C 富集柱形图
- Cluster_0.F 富集柱形图
- Cluster_0.P 富集柱形图
- Cluster_1.C 富集柱形图
- Cluster_1.F 富集柱形图
- Cluster_1.P 富集柱形图
- Cluster_2.C 富集柱形图
- Cluster_2.F 富集柱形图
- Cluster_2.P 富集柱形图
- Cluster_3.C 富集柱形图
- Cluster_3.F 富集柱形图
- Cluster_3.P 富集柱形图
- Cluster_4.C 富集柱形图
- Cluster_4.F 富集柱形图
- Cluster_4.P 富集柱形图
- Cluster_5.C 富集柱形图
- Cluster_5.F 富集柱形图
- Cluster_5.P 富集柱形图
- Cluster_6.C 富集柱形图
- Cluster_6.F 富集柱形图
- Cluster_6.P 富集柱形图
- Cluster_7.C 富集柱形图
- Cluster_7.F 富集柱形图
- Cluster_7.P 富集柱形图
- Cluster_8.C 富集柱形图
- Cluster_8.F 富集柱形图
- Cluster_8.P 富集柱形图
- Cluster_9.C 富集柱形图
- Cluster_9.F 富集柱形图
- Cluster_9.P 富集柱形图
- Cluster_10.C 富集柱形图
- Cluster_10.F 富集柱形图
- Cluster_10.P 富集柱形图
- Cluster_11.C 富集柱形图
- Cluster_11.F 富集柱形图
- Cluster_11.P 富集柱形图
- Cluster_12.C 富集柱形图
- Cluster_12.F 富集柱形图
- Cluster_12.P 富集柱形图
- Cluster_13.C 富集柱形图
- Cluster_13.F 富集柱形图
- Cluster_13.P 富集柱形图
- Cluster_14.C 富集柱形图
- Cluster_14.F 富集柱形图
- Cluster_14.P 富集柱形图
- Cluster_15.C 富集柱形图
- Cluster_15.F 富集柱形图
- Cluster_15.P 富集柱形图
- Cluster_16.C 富集柱形图
- Cluster_16.F 富集柱形图
- Cluster_16.P 富集柱形图
- Cluster_17.C 富集柱形图
- Cluster_17.F 富集柱形图
- Cluster_17.P 富集柱形图
- Cluster_18.C 富集柱形图
- Cluster_18.F 富集柱形图
- Cluster_18.P 富集柱形图
- Cluster_19.C 富集柱形图
- Cluster_19.F 富集柱形图
- Cluster_19.P 富集柱形图
- Cluster_20.C 富集柱形图
- Cluster_20.F 富集柱形图
- Cluster_20.P 富集柱形图
- Cluster_21.C 富集柱形图
- Cluster_21.F 富集柱形图
- Cluster_21.P 富集柱形图
- Cluster_22.C 富集柱形图
- Cluster_22.F 富集柱形图
- Cluster_22.P 富集柱形图
Fig 5-3-4 GO富集条形图
5.4 KO富集分析
在生物体内,不同基因相互协调行使其生物学,基于Pathway的分析有助于更进一步了解基因的生物学功能。KEGG是有关Pathway的主要公共数据库。 Pathway显著性富集分析以KEGG Pathway为单位,应用超几何检验,找出与整个基因组背景相比,在基因中显著性富集的Pathway。通过Pathway显著性富集能确定基因参与的最主要生化代谢途径和信号转导途径。
所有趋势pathway统计如下所示:
| Pathway | Pathway_ID | KEGG_A_class | KEGG_B_class | Cluster_0(276) | Cluster_0_Pvalue | Cluster_0_Qvalue | Cluster_1(772) | Cluster_1_Pvalue | Cluster_1_Qvalue | Cluster_10(436) | Cluster_10_Pvalue | Cluster_10_Qvalue | Cluster_11(361) | Cluster_11_Pvalue | Cluster_11_Qvalue | Cluster_12(268) | Cluster_12_Pvalue | Cluster_12_Qvalue | Cluster_13(377) | Cluster_13_Pvalue | Cluster_13_Qvalue | Cluster_14(374) | Cluster_14_Pvalue | Cluster_14_Qvalue | Cluster_15(850) | Cluster_15_Pvalue | Cluster_15_Qvalue | Cluster_16(524) | Cluster_16_Pvalue | Cluster_16_Qvalue | Cluster_17(291) | Cluster_17_Pvalue | Cluster_17_Qvalue | Cluster_18(168) | Cluster_18_Pvalue | Cluster_18_Qvalue | Cluster_19(634) | Cluster_19_Pvalue | Cluster_19_Qvalue | Cluster_2(296) | Cluster_2_Pvalue | Cluster_2_Qvalue | Cluster_20(271) | Cluster_20_Pvalue | Cluster_20_Qvalue | Cluster_21(209) | Cluster_21_Pvalue | Cluster_21_Qvalue | Cluster_22(167) | Cluster_22_Pvalue | Cluster_22_Qvalue | Cluster_3(270) | Cluster_3_Pvalue | Cluster_3_Qvalue | Cluster_4(325) | Cluster_4_Pvalue | Cluster_4_Qvalue | Cluster_5(344) | Cluster_5_Pvalue | Cluster_5_Qvalue | Cluster_6(398) | Cluster_6_Pvalue | Cluster_6_Qvalue | Cluster_7(522) | Cluster_7_Pvalue | Cluster_7_Qvalue | Cluster_8(238) | Cluster_8_Pvalue | Cluster_8_Qvalue | Cluster_9(351) | Cluster_9_Pvalue | Cluster_9_Qvalue |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-Oxocarboxylic acid metabolism | ko01210 | Metabolism | Global and overview maps | 0 | 1 | 1 | 5 | 0.02223178 | 1.359559e-01 | 2 | 0.2454007 | 9.743313e-01 | 0 | 1 | 1 | 0 | 1 | 1 | 4 | 0.008052936 | 8.407265e-02 | 0 | 1 | 1 | 5 | 0.03224956 | 1.737315e-01 | 1 | 0.6918823 | 9.937946e-01 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0.7615184 | 1.000000e+00 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 6 | 1.042245e-06 | 1.643540e-05 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0.5346686 | 7.668253e-01 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 2 | 0.1768851 | 5.117647e-01 |
| ABC transporters | ko02010 | Environmental Information Processing | Membrane transport | 0 | 1 | 1 | 5 | 0.5297399 | 9.736352e-01 | 0 | 1 | 1 | 2 | 0.6625046 | 1.000000e+00 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 3 | 0.9086782 | 1.000000e+00 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0.9833267 | 1.000000e+00 | 0 | 1 | 1 | 2 | 0.5054369 | 7.414926e-01 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 3 | 0.3610819 | 6.079542e-01 | 1 | 0.9207746 | 1.000000e+00 | 0 | 1 | 1 | 2 | 0.4375253 | 7.712048e-01 | 3 | 0.3730591 | 7.357263e-01 |
| AGE-RAGE signaling pathway in diabetic complications | ko04933 | Human Diseases | Endocrine and metabolic diseases | 8 | 0.01224197 | 4.252474e-02 | 13 | 0.09059233 | 3.552775e-01 | 6 | 0.3648089 | 9.968682e-01 | 6 | 0.2191226 | 7.435025e-01 | 11 | 0.0001982159 | 3.780260e-03 | 1 | 0.9870402 | 1.000000e+00 | 3 | 0.7971608 | 1.000000e+00 | 13 | 0.1554419 | 5.191759e-01 | 10 | 0.06899366 | 3.219747e-01 | 8 | 0.01639302 | 7.683508e-02 | 6 | 0.01143041 | 6.803815e-02 | 9 | 0.281177 | 9.060017e-01 | 3 | 0.650876 | 9.998671e-01 | 9 | 0.00333006 | 1.816091e-02 | 5 | 0.08577417 | 2.757027e-01 | 2 | 0.5626932 | 9.999696e-01 | 5 | 0.1864729 | 8.123856e-01 | 3 | 0.7124199 | 9.812043e-01 | 12 | 0.0004512088 | 6.111828e-03 | 5 | 0.4641543 | 9.343373e-01 | 8 | 0.2313915 | 4.264863e-01 | 5 | 0.1291796 | 4.274084e-01 | 9 | 0.01687651 | 1.963583e-01 |
| AMPK signaling pathway | ko04152 | Environmental Information Processing | Signal transduction | 7 | 0.08817096 | 1.923730e-01 | 13 | 0.2699809 | 7.055091e-01 | 3 | 0.9449017 | 9.968682e-01 | 6 | 0.3833155 | 9.997647e-01 | 4 | 0.5109679 | 7.651735e-01 | 2 | 0.9695247 | 1.000000e+00 | 3 | 0.8960059 | 1.000000e+00 | 14 | 0.286429 | 7.416069e-01 | 7 | 0.5937026 | 9.456923e-01 | 4 | 0.5764837 | 7.948874e-01 | 2 | 0.6797805 | 8.321853e-01 | 9 | 0.5187677 | 1.000000e+00 | 3 | 0.7825354 | 9.998671e-01 | 3 | 0.7293905 | 8.852148e-01 | 2 | 0.7898136 | 8.997876e-01 | 1 | 0.9045318 | 9.999696e-01 | 4 | 0.5168458 | 9.999999e-01 | 4 | 0.6637028 | 9.812043e-01 | 7 | 0.1992184 | 4.271013e-01 | 5 | 0.6506331 | 9.791958e-01 | 13 | 0.02827782 | 8.782589e-02 | 1 | 0.9652973 | 9.923214e-01 | 4 | 0.7217519 | 9.282627e-01 |
| Acute myeloid leukemia | ko05221 | Human Diseases | Cancers | 9 | 0.0003179069 | 2.797581e-03 | 9 | 0.1578767 | 5.071191e-01 | 4 | 0.4594158 | 9.968682e-01 | 5 | 0.1592604 | 7.072900e-01 | 9 | 0.0002556469 | 4.266108e-03 | 2 | 0.8081355 | 1.000000e+00 | 4 | 0.3470407 | 1.000000e+00 | 9 | 0.23197 | 6.403139e-01 | 12 | 0.0007974987 | 9.333688e-03 | 3 | 0.4095891 | 6.503915e-01 | 4 | 0.04453226 | 1.568037e-01 | 6 | 0.3919127 | 1.000000e+00 | 2 | 0.6877486 | 9.998671e-01 | 10 | 5.143303e-05 | 5.281777e-04 | 5 | 0.02514519 | 1.357840e-01 | 0 | 1 | 1 | 4 | 0.1673492 | 7.898882e-01 | 1 | 0.928854 | 9.812043e-01 | 10 | 0.0003645995 | 5.432533e-03 | 4 | 0.3908794 | 9.200698e-01 | 5 | 0.4018915 | 6.350345e-01 | 7 | 0.002748465 | 3.166710e-02 | 8 | 0.006509532 | 1.184885e-01 |
| Adherens junction | ko04520 | Cellular Processes | Cellular community - eukaryotes | 10 | 5.3179e-05 | 5.849690e-04 | 11 | 0.0371912 | 1.935996e-01 | 3 | 0.6719816 | 9.968682e-01 | 4 | 0.3143502 | 9.061541e-01 | 3 | 0.3516197 | 6.298840e-01 | 1 | 0.9518116 | 1.000000e+00 | 0 | 1 | 1 | 10 | 0.1262662 | 4.584012e-01 | 1 | 0.9857447 | 1.000000e+00 | 8 | 0.001910327 | 1.780918e-02 | 7 | 0.0003296866 | 5.494777e-03 | 10 | 0.02545491 | 2.882321e-01 | 4 | 0.2023665 | 9.812866e-01 | 4 | 0.1631565 | 3.485023e-01 | 6 | 0.005822473 | 4.912712e-02 | 0 | 1 | 1 | 4 | 0.1616513 | 7.898882e-01 | 7 | 0.01345409 | 1.702151e-01 | 6 | 0.05243201 | 1.860088e-01 | 6 | 0.09143808 | 4.531596e-01 | 10 | 0.007235353 | 3.000543e-02 | 5 | 0.03865762 | 2.008680e-01 | 6 | 0.05677204 | 3.192088e-01 |
| Adipocytokine signaling pathway | ko04920 | Organismal Systems | Endocrine system | 6 | 0.01962436 | 6.167656e-02 | 5 | 0.7240991 | 1.000000e+00 | 1 | 0.9688813 | 9.968682e-01 | 2 | 0.7750706 | 1.000000e+00 | 6 | 0.01722917 | 8.480070e-02 | 0 | 1 | 1 | 2 | 0.7918626 | 1.000000e+00 | 9 | 0.2082882 | 6.124830e-01 | 6 | 0.2183004 | 6.029887e-01 | 2 | 0.6637518 | 8.409648e-01 | 1 | 0.732072 | 8.434009e-01 | 4 | 0.7324608 | 1.000000e+00 | 2 | 0.6729554 | 9.998671e-01 | 8 | 0.00110807 | 7.215968e-03 | 1 | 0.8064462 | 9.072520e-01 | 1 | 0.7299437 | 9.999696e-01 | 2 | 0.6228706 | 9.999999e-01 | 0 | 1 | 1 | 2 | 0.7513731 | 8.932500e-01 | 1 | 0.9576032 | 1.000000e+00 | 1 | 0.9846229 | 1.000000e+00 | 0 | 1 | 1 | 5 | 0.1348926 | 4.659478e-01 |
| Adrenergic signaling in cardiomyocytes | ko04261 | Organismal Systems | Circulatory system | 7 | 0.1543705 | 2.890341e-01 | 14 | 0.3539771 | 8.078413e-01 | 4 | 0.9240723 | 9.968682e-01 | 5 | 0.6920747 | 1.000000e+00 | 8 | 0.06605158 | 2.260996e-01 | 5 | 0.7280139 | 1.000000e+00 | 6 | 0.5575421 | 1.000000e+00 | 9 | 0.9361987 | 1.000000e+00 | 8 | 0.6075175 | 9.456923e-01 | 11 | 0.00699949 | 3.890101e-02 | 4 | 0.2827743 | 5.236561e-01 | 11 | 0.4373094 | 1.000000e+00 | 3 | 0.858375 | 9.998671e-01 | 6 | 0.2676222 | 4.828049e-01 | 6 | 0.1189675 | 3.417152e-01 | 11 | 7.288991e-05 | 8.301351e-04 | 4 | 0.6328264 | 9.999999e-01 | 7 | 0.2653522 | 9.681769e-01 | 9 | 0.1007776 | 2.945201e-01 | 7 | 0.455608 | 9.343373e-01 | 18 | 0.001666409 | 9.720753e-03 | 6 | 0.1825315 | 4.885944e-01 | 6 | 0.4949155 | 8.148333e-01 |
| African trypanosomiasis | ko05143 | Human Diseases | Infectious diseases | 1 | 0.9923093 | 1.000000e+00 | 3 | 0.9998978 | 1.000000e+00 | 3 | 0.9825323 | 9.968682e-01 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0.9987533 | 1.000000e+00 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0.999915 | 1.000000e+00 | 1 | 0.9941226 | 1.000000e+00 | 0 | 1 | 1 | 3 | 0.9990753 | 1.000000e+00 | 3 | 0.8893537 | 9.998671e-01 | 3 | 0.8506873 | 9.456345e-01 | 1 | 0.9745802 | 9.929685e-01 | 0 | 1 | 1 | 0 | 1 | 1 | 3 | 0.9228639 | 9.812043e-01 | 2 | 0.9835481 | 1.000000e+00 | 0 | 1 | 1 | 2 | 0.9990563 | 1.000000e+00 | 1 | 0.9848322 | 9.923214e-01 | 1 | 0.9980044 | 1.000000e+00 |
| Alanine, aspartate and glutamate metabolism | ko00250 | Metabolism | Amino acid metabolism | 0 | 1 | 1 | 2 | 0.8413715 | 1.000000e+00 | 2 | 0.5451229 | 9.968682e-01 | 0 | 1 | 1 | 2 | 0.3052139 | 5.854740e-01 | 2 | 0.4666772 | 1.000000e+00 | 1 | 0.7949571 | 1.000000e+00 | 4 | 0.4733011 | 9.580762e-01 | 1 | 0.8934442 | 1.000000e+00 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0.9345428 | 1.000000e+00 | 0 | 1 | 1 | 2 | 0.3098394 | 5.269243e-01 | 0 | 1 | 1 | 2 | 0.1516497 | 6.476706e-01 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0.6323661 | 8.972937e-01 | 2 | 0.4298153 | 7.762725e-01 |
KO富集圈图:(第一圈:富集前20的pathway,圈外为基因数目的坐标尺。不同的颜色代表不同的A class; 第二圈:背景基因中该pathway的数目以及Q值。基因越多条形越长,Q值越小颜色越红; 第三圈:该pathway差异基因数量 第四圈:各pathway的RichFactor值(该pathway中差异数量除以所有数量),背景网格线,每一格代表0.1)
- Cluster_0 富集圈图
- Cluster_1 富集圈图
- Cluster_2 富集圈图
- Cluster_3 富集圈图
- Cluster_4 富集圈图
- Cluster_5 富集圈图
- Cluster_6 富集圈图
- Cluster_7 富集圈图
- Cluster_8 富集圈图
- Cluster_9 富集圈图
- Cluster_10 富集圈图
- Cluster_11 富集圈图
- Cluster_12 富集圈图
- Cluster_13 富集圈图
- Cluster_14 富集圈图
- Cluster_15 富集圈图
- Cluster_16 富集圈图
- Cluster_17 富集圈图
- Cluster_18 富集圈图
- Cluster_19 富集圈图
- Cluster_20 富集圈图
- Cluster_21 富集圈图
- Cluster_22 富集圈图
Fig 5-4-1 KO 富集圈图
KO富集气泡图:(利用Q值最小的前20个pathway来作图,纵坐标为pathway,横坐标为富集因子(该pathway中差异数量除以所有数量),大小表示数量多少,颜色越红Q值越小)");
- Cluster_0
- Cluster_1
- Cluster_2
- Cluster_3
- Cluster_4
- Cluster_5
- Cluster_6
- Cluster_7
- Cluster_8
- Cluster_9
- Cluster_10
- Cluster_11
- Cluster_12
- Cluster_13
- Cluster_14
- Cluster_15
- Cluster_16
- Cluster_17
- Cluster_18
- Cluster_19
- Cluster_20
- Cluster_21
- Cluster_22
Fig 5-4-2 KO富集气泡图
KO富集条形图:(利用Q值最小的前20个pathway来作图,纵坐标为pathway,横坐标为该pathway数目占所有差异数目的百分比,颜色越深Q值越小,柱子上的数值为该pathway数量及Q值");
- Cluster_0 富集柱形图
- Cluster_1 富集柱形图
- Cluster_2 富集柱形图
- Cluster_3 富集柱形图
- Cluster_4 富集柱形图
- Cluster_5 富集柱形图
- Cluster_6 富集柱形图
- Cluster_7 富集柱形图
- Cluster_8 富集柱形图
- Cluster_9 富集柱形图
- Cluster_10 富集柱形图
- Cluster_11 富集柱形图
- Cluster_12 富集柱形图
- Cluster_13 富集柱形图
- Cluster_14 富集柱形图
- Cluster_15 富集柱形图
- Cluster_16 富集柱形图
- Cluster_17 富集柱形图
- Cluster_18 富集柱形图
- Cluster_19 富集柱形图
- Cluster_20 富集柱形图
- Cluster_21 富集柱形图
- Cluster_22 富集柱形图
Fig 5-4-3 KO富集条形图
5.5 Reactome富集分析
Reactome数据库汇集了部分物种各项反应及生物学通路。我们将基因向Reactome数据库(https://reactome.org/)的各term映射,并计算每个term的基因数,从而得到具有某个Reactome功能的基因列表及基因数目统计。然后应用超几何检验,找出与整个基因组背景相比,在基因中显著富集的Reactome条目。
Reactome富集圈图:(第一圈:富集前20的Reactome通路,圈外为基因数目的坐标尺。 第二圈:背景基因中该Reactome通路的数目以及Q值。基因越多条形越长,Q值越小颜色越红; 第三圈:该Reactome通路差异基因数量 第四圈:各Reactome通路的RichFactor值(该Reactome通路中差异数量除以所有数量),背景网格线,每一格代表0.1)
- Cluster_0 富集圈图
- Cluster_1 富集圈图
- Cluster_2 富集圈图
- Cluster_3 富集圈图
- Cluster_4 富集圈图
- Cluster_5 富集圈图
- Cluster_6 富集圈图
- Cluster_7 富集圈图
- Cluster_8 富集圈图
- Cluster_9 富集圈图
- Cluster_10 富集圈图
- Cluster_11 富集圈图
- Cluster_12 富集圈图
- Cluster_13 富集圈图
- Cluster_14 富集圈图
- Cluster_15 富集圈图
- Cluster_16 富集圈图
- Cluster_17 富集圈图
- Cluster_18 富集圈图
- Cluster_19 富集圈图
- Cluster_20 富集圈图
- Cluster_21 富集圈图
- Cluster_22 富集圈图
Fig 5-5-1 Reactome 富集圈图
Reactome富集气泡图:(利用Q值最小的前20个Reactome通路来作图,纵坐标为Reactome通路,横坐标为富集因子(该Reactome通路中差异数量除以所有数量),大小表示数量多少,颜色越红Q值越小)");
- Cluster_0
- Cluster_1
- Cluster_2
- Cluster_3
- Cluster_4
- Cluster_5
- Cluster_6
- Cluster_7
- Cluster_8
- Cluster_9
- Cluster_10
- Cluster_11
- Cluster_12
- Cluster_13
- Cluster_14
- Cluster_15
- Cluster_16
- Cluster_17
- Cluster_18
- Cluster_19
- Cluster_20
- Cluster_21
- Cluster_22
Fig 5-5-2 Reactome富集气泡图
Reactome富集条形图:(利用Q值最小的前20个Reactome通路来作图,纵坐标为Reactome通路,横坐标为该Reactome通路数目占所有差异数目的百分比,颜色越深Q值越小,柱子上的数值为该Reactome通路数量及Q值");
- Cluster_0 富集柱形图
- Cluster_1 富集柱形图
- Cluster_2 富集柱形图
- Cluster_3 富集柱形图
- Cluster_4 富集柱形图
- Cluster_5 富集柱形图
- Cluster_6 富集柱形图
- Cluster_7 富集柱形图
- Cluster_8 富集柱形图
- Cluster_9 富集柱形图
- Cluster_10 富集柱形图
- Cluster_11 富集柱形图
- Cluster_12 富集柱形图
- Cluster_13 富集柱形图
- Cluster_14 富集柱形图
- Cluster_15 富集柱形图
- Cluster_16 富集柱形图
- Cluster_17 富集柱形图
- Cluster_18 富集柱形图
- Cluster_19 富集柱形图
- Cluster_20 富集柱形图
- Cluster_21 富集柱形图
- Cluster_22 富集柱形图
Fig 5-5-3 Reactome富集条形图
5.6 上调基因蛋白质互作网络分析
通过string数据库[11],我们可以获得上调基因构建蛋白质互作关系信息(3.MarkerGene/String),然后利用Cytoscape构建蛋白质互作网络图。
注:依据系统配置及浏览器不同,如果标记基因数量过多该图可能不能正常加载,请使用桌面版Cytoscape软件
Cytoscape官方手册:http://manual.cytoscape.org/en/stable/index.html
Cytoscape使用教程:http://www.omicshare.com/class/home/index/classdetail?id=14
6 GSVA分析
基于传统的超几何检验的富集分析,往往需要用到显著差异基因集数据。当单个基因变化较为微弱时,基于传统富集分析得到结果可能会很少,甚至没有结果。GSVA分析(Gene Set Variation Analysis)[12]能够有效弥补传统富集分析对微效基因的有效信息挖据不足等问题,更为全面地对某一功能单位的调节作用进行解释。GSVA分析反映了某一个细胞亚群相对于所有细胞过表达的通路信息。GSVA原理如下:
- 将每个基因在所有cluster的表达量分布情况进行统计,然后将基因在每个样本中按照表达量从高到低进行排序
- 分析特定基因集是否在所有基因中的排名更为靠前或靠后,然后对基因集在每个样本中的富集程度进行打分,即富集分数(Enrichment Score, ES)
我们对MSigDB数据库的八个数据集的每个通路进行GSVA分析
MSigDB数据库各数据集在各细胞富集程度表:
- H: 4.GSVA/H.gsva.xls
- C1: 4.GSVA/C1.gsva.xls
- C2: 4.GSVA/C2.gsva.xls
- C3: 4.GSVA/C3.gsva.xls
- C4: 4.GSVA/C4.gsva.xls
- C5: 4.GSVA/C5.gsva.xls
- C6: 4.GSVA/C6.gsva.xls
- C7: 4.GSVA/C7.gsva.xls
- H
- C1
- C2
- C3
- C4
- C5
- C6
- C7
Fig 6-0-1 各个亚群中的富集分数热图
7 转录因子注释
转录因子是调控基因表达的重要元件,其表达情况与细胞的下游基因表达和上游表观调控息息相关。为了方便转录因子分析的进行,我们使用animalTFDB(对动物样本)或者plantTFDB(对植物样本)对样本中所有有表达的转录因子进行注释。
| gene_id | TF_family | Gene_name | Cluster 0 | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 | Cluster 7 | Cluster 8 | Cluster 9 | Cluster 10 | Cluster 11 | Cluster 12 | Cluster 13 | Cluster 14 | Cluster 15 | Cluster 16 | Cluster 17 | Cluster 18 | Cluster 19 | Cluster 20 | Cluster 21 | Cluster 22 | Description | KEGG_A_class | KEGG_B_class | Pathway | K_ID | GO Component | GO Function | GO Process |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ENSMUSG00000052713 | Others | Zfp608 | 1.063103001594 | 1.0940523561116 | 1.32996401257749 | 0.0576215586075214 | 1.67049282014792 | 1.29130506904182 | 0.0367290917762288 | 0.0556866876333238 | 0.509700217511249 | 0.567783957855158 | 0.102437919782043 | 0.0549665527158597 | 0.932850158130764 | 0.373038491899366 | 0.402834690138172 | 0.312571234118871 | 0.590261744341255 | 1.89425296842007 | 0.838711633593396 | 0.72868982036074 | 0.269822773573052 | 0.709674398400139 | 0.163990647626932 | zinc finger protein 608 [Source:MGI Symbol;Acc:MGI:2442338] | - | - | - | - | GO:0005634//nucleus | GO:0046872//metal ion binding | GO:0000122//negative regulation of transcription by RNA polymerase II;GO:0006357//regulation of transcription by RNA polymerase II;GO:0033085//negative regulation of T cell differentiation in thymus |
| ENSMUSG00000021359 | AP-2 | Tfap2a | 0 | 0 | 0 | 9.54049721636913e-04 | 0 | 0 | 0.00394260385947877 | 0 | 0 | 0.0058599884675427 | 0.00154937869914164 | 0.00724817309797066 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | transcription factor AP-2, alpha [Source:MGI Symbol;Acc:MGI:104671] | - | - | - | - | GO:0005634//nucleus | GO:0003700//DNA-binding transcription factor activity | GO:0006355//regulation of transcription, DNA-templated |
| ENSMUSG00000033863 | zf-C2H2 | Klf9 | 0.0391888667364225 | 0.395889194261229 | 0.101241811797995 | 0.0545510552175589 | 0.101789483751204 | 0.343484015940524 | 0.170167219682777 | 0.138693729059875 | 0.267834756190776 | 0.0840346847454448 | 0.0816553666848317 | 0.0649846523863988 | 0.395045309479044 | 0.12540395885361 | 0.744120985960337 | 0.881119115703809 | 0.592650032688294 | 0.377123914115303 | 1.76589807723274 | 0.189713301818008 | 0 | 0 | 1.07533983232231 | Kruppel-like factor 9 [Source:MGI Symbol;Acc:MGI:1333856] | - | - | - | - | GO:0005634//nucleus;GO:0005654//nucleoplasm;GO:0005829//cytosol;GO:0005886//plasma membrane | - | GO:0007623//circadian rhythm;GO:0010839//negative regulation of keratinocyte proliferation;GO:0071387//cellular response to cortisol stimulus;GO:0097067//cellular response to thyroid hormone stimulus |
| ENSMUSG00000021514 | zf-C2H2 | Zfp369 | 0.0101912404854793 | 0.125447114334783 | 0.176031352058246 | 0.271593805460094 | 0.178330971559988 | 0.161897611914904 | 0.204983007986545 | 0.194553736644023 | 0.217341943677359 | 0.170603240219728 | 0.140394783288873 | 0.224705915344942 | 0.155850546017482 | 0.0621236386020273 | 0.262317913159328 | 0.108718003990678 | 0.0336882866936466 | 0.183778702469645 | 0.147006942547616 | 0.0883426615926012 | 0.112177093176175 | 0.0295775731009719 | 0.143820741827386 | zinc finger protein 369 [Source:MGI Symbol;Acc:MGI:2176229] | Organismal Systems | Nervous system | ko04722//Neurotrophin signaling pathway | K12458 | GO:0005634//nucleus | GO:0003677//DNA binding;GO:0046872//metal ion binding | GO:0006355//regulation of transcription, DNA-templated |
| ENSMUSG00000045903 | bHLH | Npas4 | 0 | 0.00125480705071718 | 0 | 0 | 0 | 0.00182040734891165 | 0.00200005560154572 | 0 | 0 | 0 | 0 | 0 | 0 | 0.00522310492695488 | 0 | 0.00227065529976624 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | neuronal PAS domain protein 4 [Source:MGI Symbol;Acc:MGI:2664186] | - | - | - | - | GO:0005634//nucleus;GO:0005667//transcription factor complex;GO:0098794//postsynapse | GO:0000977//RNA polymerase II regulatory region sequence-specific DNA binding;GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0001228//DNA-binding transcription activator activity, RNA polymerase II-specific;GO:0003677//DNA binding;GO:0005515//protein binding;GO:0044877//protein-containing complex binding;GO:0046982//protein heterodimerization activity;GO:0046983//protein dimerization activity | GO:0006357//regulation of transcription by RNA polymerase II;GO:0007399//nervous system development;GO:0007612//learning;GO:0007614//short-term memory;GO:0007616//long-term memory;GO:0030154//cell differentiation;GO:0032228//regulation of synaptic transmission, GABAergic;GO:0035176//social behavior;GO:0045893//positive regulation of transcription, DNA-templated;GO:0045944//positive regulation of transcription by RNA polymerase II;GO:0048167//regulation of synaptic plasticity;GO:0060079//excitatory postsynaptic potential;GO:0060080//inhibitory postsynaptic potential;GO:0071386//cellular response to corticosterone stimulus;GO:1904862//inhibitory synapse assembly |
| ENSMUSG00000021362 | GCM | Gcm2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0707731885763849 | 0 | 0 | 0 | glial cells missing homolog 2 [Source:MGI Symbol;Acc:MGI:1861438] | Organismal Systems | Endocrine system | ko04928//Parathyroid hormone synthesis, secretion and action | K21598 | GO:0005634//nucleus | GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0001228//DNA-binding transcription activator activity, RNA polymerase II-specific;GO:0003677//DNA binding;GO:0043565//sequence-specific DNA binding;GO:1990837//sequence-specific double-stranded DNA binding | GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II;GO:0006366//transcription by RNA polymerase II;GO:0006874//cellular calcium ion homeostasis;GO:0007275//multicellular organism development;GO:0030643//cellular phosphate ion homeostasis;GO:0045944//positive regulation of transcription by RNA polymerase II;GO:0060017//parathyroid gland development |
| ENSMUSG00000036721 | zf-C2H2 | Zscan12 | 0.00349540422726097 | 0.0691825815224645 | 0.0162058094390252 | 0.0825761656062313 | 0.0407334513660977 | 0.0757042626135363 | 0.0523348553188687 | 0.0286647753927316 | 0.130595068924246 | 0.0982594571506073 | 0.0232776997590043 | 0.0617456346261728 | 0.125303092842355 | 0.0589389622149604 | 0.0547618347066167 | 0.0435555280145042 | 0.0311245985030864 | 0.0732903802641637 | 0.0119368065461447 | 0.0338467864283964 | 0 | 0 | 0 | zinc finger and SCAN domain containing 12 [Source:MGI Symbol;Acc:MGI:1099444] | - | - | - | - | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0003677//DNA binding;GO:0046872//metal ion binding | GO:0006357//regulation of transcription by RNA polymerase II |
| ENSMUSG00000042320 | HPD | Prox2 | 0 | 0.0074634161538697 | 0.0301391117819175 | 0.01042809687227 | 0.0060668927382487 | 0.00790064085897658 | 0.0217279316664823 | 0.0148339710408516 | 0 | 0.00283831912470779 | 0.0246720818508643 | 0.0203488180968512 | 0.00249743263924685 | 0 | 0.0268297315598311 | 0.00241329862688135 | 0 | 0 | 0 | 0.0142168236203994 | 0 | 0.0457021681108552 | 0 | prospero homeobox 2 [Source:MGI Symbol;Acc:MGI:1920672] | - | - | - | - | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0003677//DNA binding | GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II |
| ENSMUSG00000090641 | zf-C2H2 | Zfp712 | 0.00690313578579491 | 0.0251294097227143 | 0.067025375394017 | 0.0901208249932341 | 0.0567205095888074 | 0.0246591160597718 | 0.080013443536385 | 0.0994730470298476 | 0.0556438751909932 | 0.0224897178580637 | 0.041829529905036 | 0.0806728800756413 | 0.0156451239598279 | 0.019434460451021 | 0.12904080931268 | 0.0157203411289135 | 0 | 0 | 0 | 0.13444453924901 | 0 | 0 | 0 | zinc finger protein 712 [Source:MGI Symbol;Acc:MGI:1925501] | Human Diseases | Infectious diseases | ko05168//Herpes simplex infection | K09228 | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0046872//metal ion binding | GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II |
| ENSMUSG00000058883 | zf-C2H2 | Zfp708 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.00214777324239661 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | zinc finger protein 708 [Source:MGI Symbol;Acc:MGI:3040674] | Human Diseases | Infectious diseases | ko05168//Herpes simplex infection | K09228 | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0046872//metal ion binding | GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II |
| ENSMUSG00000021327 | zf-C2H2 | Zkscan3 | 0.149103583808304 | 0.74063504372502 | 0.808800547816522 | 0.874445910218706 | 0.694338329273342 | 0.784567091154161 | 0.928771270135491 | 0.874258860779313 | 1.03154209599426 | 0.874477418796302 | 0.738252528829725 | 1.01294749112394 | 0.816869165161249 | 0.631412942500516 | 1.01251532851658 | 0.435288082515299 | 0.744795750275878 | 0.320868111311838 | 0.590487113642067 | 1.27428626126603 | 2.0654035798086 | 0.141170048943152 | 0.533876259599236 | zinc finger with KRAB and SCAN domains 3 [Source:MGI Symbol;Acc:MGI:1919989] | - | - | - | - | GO:0005634//nucleus | GO:0003677//DNA binding;GO:0046872//metal ion binding | GO:0006355//regulation of transcription, DNA-templated |
| ENSMUSG00000100235 | zf-C2H2 | Gm28557 | 7.3345605520049e-04 | 0.00929808070838625 | 0.00761267311485772 | 0.0101903717450177 | 0.0209889478978266 | 0.0214529427020955 | 0.00890988537195195 | 0.00719058841831525 | 0.0116677605959037 | 0.00329069903661495 | 0.00127477038198494 | 0.00987256659459134 | 0.0195722145307678 | 0.015965666858107 | 0.0189105177936153 | 0.0120153391455787 | 0.0131182882932028 | 0.017424031223864 | 0 | 0 | 0 | 0 | 0 | predicted gene 28557 [Source:MGI Symbol;Acc:MGI:5579263] | Human Diseases | Infectious diseases | ko05168//Herpes simplex infection | K09228 | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0046872//metal ion binding | GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II |
| ENSMUSG00000074824 | zf-C2H2 | Rslcan18 | 0 | 0.00260692662765784 | 0 | 0 | 0 | 0 | 0.00266319315261082 | 0.00283065520326793 | 0 | 0 | 0.00375242191866155 | 0 | 0 | 0.00280565901423171 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | regulator of sex-limitation candidate 18 [Source:MGI Symbol;Acc:MGI:5433745] | Human Diseases | Infectious diseases | ko05168//Herpes simplex infection | K09228 | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0046872//metal ion binding | GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II |
| ENSMUSG00000057396 | zf-C2H2 | Zfp759 | 0.00550250666824971 | 0.0278758485337064 | 0.0309492927541174 | 0.0537174143092072 | 0.0289548808637963 | 0.0322826493356756 | 0.0584925521845877 | 0.080141135253695 | 0.053359501371562 | 0.0445703670172376 | 0.0114412094042048 | 0.0449867643811875 | 0.0379261638154441 | 0.0291829199733984 | 0.0541270941439582 | 0.0230674077665037 | 0.0101108145272183 | 0.0274363476733977 | 0.0343236860892965 | 0.140566097003865 | 0 | 0 | 0 | zinc finger protein 759 [Source:MGI Symbol;Acc:MGI:2446280] | Human Diseases | Infectious diseases | ko05168//Herpes simplex infection | K09228 | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0001228//DNA-binding transcription activator activity, RNA polymerase II-specific;GO:0046872//metal ion binding | GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II;GO:0045944//positive regulation of transcription by RNA polymerase II |
| ENSMUSG00000022676 | zf-C2H2 | Snai2 | 0 | 1.56581654624024e-04 | 0 | 0 | 0 | 0 | 0.00270678616798159 | 0 | 0.0120784554909808 | 0 | 0 | 0 | 0 | 0.0135204564506098 | 0 | 0.037976759422333 | 0 | 0 | 0.11227528659324 | 0 | 0 | 0 | 0 | snail family zinc finger 2 [Source:MGI Symbol;Acc:MGI:1096393] | Environmental Information Processing;Cellular Processes | Signal transduction;Cellular community - eukaryotes | ko04390//Hippo signaling pathway;ko04520//Adherens junction | K05706;K05706 | GO:0000785//chromatin;GO:0005634//nucleus;GO:0005737//cytoplasm | GO:0000977//RNA polymerase II regulatory region sequence-specific DNA binding;GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0001227//DNA-binding transcription repressor activity, RNA polymerase II-specific;GO:0003677//DNA binding;GO:0003682//chromatin binding;GO:0005515//protein binding;GO:0043565//sequence-specific DNA binding;GO:0046872//metal ion binding;GO:0070888//E-box binding;GO:1990837//sequence-specific double-stranded DNA binding | GO:0000122//negative regulation of transcription by RNA polymerase II;GO:0001837//epithelial to mesenchymal transition;GO:0003198//epithelial to mesenchymal transition involved in endocardial cushion formation;GO:0003273//cell migration involved in endocardial cushion formation;GO:0006355//regulation of transcription, DNA-templated;GO:0006929//substrate-dependent cell migration;GO:0006933//negative regulation of cell adhesion involved in substrate-bound cell migration;GO:0007219//Notch signaling pathway;GO:0007275//multicellular organism development;GO:0007605//sensory perception of sound;GO:0009314//response to radiation;GO:0010839//negative regulation of keratinocyte proliferation;GO:0010957//negative regulation of vitamin D biosynthetic process;GO:0014032//neural crest cell development;GO:0016477//cell migration;GO:0030335//positive regulation of cell migration;GO:0032331//negative regulation of chondrocyte differentiation;GO:0032642//regulation of chemokine production;GO:0033629//negative regulation of cell adhesion mediated by integrin;GO:0035066//positive regulation of histone acetylation;GO:0035921//desmosome disassembly;GO:0036120//cellular response to platelet-derived growth factor stimulus;GO:0042981//regulation of apoptotic process;GO:0043066//negative regulation of apoptotic process;GO:0043473//pigmentation;GO:0043518//negative regulation of DNA damage response, signal transduction by p53 class mediator;GO:0044319//wound healing, spreading of cells;GO:0045600//positive regulation of fat cell differentiation;GO:0045667//regulation of osteoblast differentiation;GO:0050872//white fat cell differentiation;GO:0060021//roof of mouth development;GO:0060429//epithelium development;GO:0060536//cartilage morphogenesis;GO:0060693//regulation of branching involved in salivary gland morphogenesis;GO:0070563//negative regulation of vitamin D receptor signaling pathway;GO:0071364//cellular response to epidermal growth factor stimulus;GO:0071479//cellular response to ionizing radiation;GO:0090090//negative regulation of canonical Wnt signaling pathway;GO:1902230//negative regulation of intrinsic apoptotic signaling pathway in response to DNA damage;GO:2000647//negative regulation of stem cell proliferation;GO:2000810//regulation of bicellular tight junction assembly;GO:2000811//negative regulation of anoikis;GO:2001028//positive regulation of endothelial cell chemotaxis;GO:2001240//negative regulation of extrinsic apoptotic signaling pathway in absence of ligand |
| ENSMUSG00000022228 | zf-C2H2 | Zscan26 | 0.0241748131365189 | 0.523089807083716 | 0.392323127865097 | 0.568988421065753 | 0.147399704914748 | 0.564832184702906 | 0.521464580509055 | 0.512662937315889 | 0.732903001463218 | 0.4849925087102 | 0.392174303199801 | 0.401706809645164 | 0.443690754035048 | 0.40860222133871 | 0.895119402665905 | 0.368043015269769 | 0.57045292378689 | 0.458738199411164 | 0.387208245584947 | 0.312591958590714 | 0.328505622424803 | 0.0923534144327423 | 0.18973812230604 | zinc finger and SCAN domain containing 26 [Source:MGI Symbol;Acc:MGI:3531417] | - | - | - | - | GO:0005634//nucleus;GO:0005654//nucleoplasm;GO:0005829//cytosol | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0046872//metal ion binding | GO:0006357//regulation of transcription by RNA polymerase II |
| ENSMUSG00000024276 | zf-C2H2 | Zfp397 | 0.147964375999767 | 0.360677150986156 | 0.702858962111333 | 0.666737880713205 | 0.667123104445406 | 0.534061265933989 | 0.581409682816369 | 0.565647812221327 | 0.535240792465312 | 0.485033252550572 | 0.404991661554993 | 0.564599158514776 | 0.351655078150096 | 0.280699715946715 | 0.802130426186561 | 0.360671870839561 | 0.418578919923387 | 0.218608259823829 | 0.351954472186238 | 0.398902056142945 | 0.553906064519613 | 0.242535595351964 | 0.0770036345715518 | zinc finger protein 397 [Source:MGI Symbol;Acc:MGI:1916506] | - | - | - | - | GO:0005634//nucleus;GO:0005730//nucleolus;GO:0005737//cytoplasm;GO:0005829//cytosol;GO:0005886//plasma membrane;GO:0015630//microtubule cytoskeleton | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0042803//protein homodimerization activity;GO:0046982//protein heterodimerization activity | GO:0006357//regulation of transcription by RNA polymerase II;GO:0045892//negative regulation of transcription, DNA-templated |
| ENSMUSG00000058900 | zf-C2H2 | Rsl1 | 0.00267096447540512 | 0.0318225517898667 | 0.049245623381233 | 0.0196845123147317 | 0.0552715568637881 | 0.0312162274349288 | 0.0505099954768975 | 0.0254544227587976 | 0.0400819931757662 | 0.0178807238893818 | 0.034671373084068 | 0.0270262599412327 | 0.015415569257201 | 0.00779253652410601 | 0.0411672598161091 | 0.0090512033807379 | 0.0203426109582114 | 0.0262136940337632 | 0 | 0.0258755863401103 | 0.045122688590277 | 0 | 0 | regulator of sex limited protein 1 [Source:MGI Symbol;Acc:MGI:3044162] | Human Diseases | Infectious diseases | ko05168//Herpes simplex infection | K09228 | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0000987//proximal promoter sequence-specific DNA binding;GO:0043565//sequence-specific DNA binding;GO:0046872//metal ion binding | GO:0000122//negative regulation of transcription by RNA polymerase II;GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II;GO:0007530//sex determination;GO:0044030//regulation of DNA methylation;GO:0045892//negative regulation of transcription, DNA-templated |
| ENSMUSG00000063281 | zf-C2H2 | Zfp35 | 0.0234255357211107 | 0.0723272750493519 | 0.0984957956771183 | 0.0840102253011415 | 0.17604958989209 | 0.0676023532559763 | 0.0767489092861162 | 0.0940871383167607 | 0.095546634253782 | 0.0976782969788755 | 0.0777256188716136 | 0.0478355044104566 | 0.0804552985941811 | 0.129713825312737 | 0.0992285376246313 | 0.0705722137455149 | 0.0312137145619281 | 0.332475259818036 | 0.0951945970182376 | 0.0859229870654566 | 0 | 0.131890553118736 | 0 | zinc finger protein 35 [Source:MGI Symbol;Acc:MGI:99179] | Human Diseases | Infectious diseases | ko05168//Herpes simplex infection | K09228 | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0001228//DNA-binding transcription activator activity, RNA polymerase II-specific;GO:0003677//DNA binding;GO:0046872//metal ion binding | GO:0002437//inflammatory response to antigenic stimulus;GO:0002829//negative regulation of type 2 immune response;GO:0006357//regulation of transcription by RNA polymerase II;GO:0007275//multicellular organism development;GO:0007283//spermatogenesis;GO:0030154//cell differentiation;GO:0045629//negative regulation of T-helper 2 cell differentiation;GO:0045944//positive regulation of transcription by RNA polymerase II |
| ENSMUSG00000051469 | zf-C2H2 | Zfp24 | 0.112276017773821 | 0.227322778464934 | 0.330774350803541 | 0.310212100573156 | 0.36901286781467 | 0.231522859825326 | 0.274451014083141 | 0.325299627067382 | 0.277680694939358 | 0.284057819082064 | 0.287315234894124 | 0.265764396179488 | 0.138121706305937 | 0.224564771809147 | 0.474531126169957 | 0.158043648849051 | 0.30057968046404 | 0.182017682546029 | 0.491904169435626 | 0.44883328923007 | 0.0744048695280642 | 0 | 0 | zinc finger protein 24 [Source:MGI Symbol;Acc:MGI:1929704] | - | - | - | - | GO:0005634//nucleus;GO:0005654//nucleoplasm | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0001228//DNA-binding transcription activator activity, RNA polymerase II-specific;GO:0003677//DNA binding;GO:0003700//DNA-binding transcription factor activity;GO:0042802//identical protein binding;GO:0043565//sequence-specific DNA binding;GO:0046872//metal ion binding | GO:0006357//regulation of transcription by RNA polymerase II;GO:0042552//myelination;GO:0045892//negative regulation of transcription, DNA-templated;GO:0045944//positive regulation of transcription by RNA polymerase II |
8 膜蛋白注释
使用TMHMM预测基因的跨膜结构域。
| GeneID | Length | ExpAA | First60 | PredHel | Topology | Gene_name | Cluster 0 | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 | Cluster 7 | Cluster 8 | Cluster 9 | Cluster 10 | Cluster 11 | Cluster 12 | Cluster 13 | Cluster 14 | Cluster 15 | Cluster 16 | Cluster 17 | Cluster 18 | Cluster 19 | Cluster 20 | Cluster 21 | Cluster 22 | Description | KEGG_A_class | KEGG_B_class | Pathway | K_ID | GO Component | GO Function | GO Process |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ENSMUSG00000000001 | 354 | 0.74 | 0.00 | 0 | o | Gnai3 | 1.79755157039878 | 0.875664517989295 | 0.734276960379285 | 0.69026629924127 | 0.891424710753902 | 0.758692819133927 | 0.848224284608358 | 1.27796271869213 | 0.638797843852811 | 0.52885357059566 | 0.664358239180385 | 0.841091192852015 | 0.555385497945661 | 0.79414682390614 | 0.940978623351753 | 0.888613938904067 | 0.74943405692772 | 2.1765242098954 | 1.02243026286555 | 0.884768368131453 | 2.7008941900215 | 1.84125352409588 | 0.061955565468446 | guanine nucleotide binding protein (G protein), alpha inhibiting 3 [Source:MGI Symbol;Acc:MGI:95773] | Human Diseases;Human Diseases;Environmental Information Processing;Human Diseases;Environmental Information Processing;Human Diseases;Organismal Systems;Organismal Systems;Environmental Information Processing;Human Diseases;Organismal Systems;Human Diseases;Organismal Systems;Organismal Systems;Organismal Systems;Organismal Systems;Environmental Information Processing;Organismal Systems;Organismal Systems;Human Diseases;Organismal Systems;Environmental Information Processing;Organismal Systems;Organismal Systems;Organismal Systems;Organismal Systems;Human Diseases;Organismal Systems;Organismal Systems;Organismal Systems;Human Diseases;Organismal Systems;Organismal Systems;Cellular Processes;Human Diseases;Organismal Systems;Organismal Systems;Organismal Systems;Organismal Systems;Human Diseases | Cancers;Infectious disease: viral;Signal transduction;Infectious diseases;Signal transduction;Substance dependence;Immune system;Development;Signal transduction;Endocrine and metabolic diseases;Endocrine system;Infectious diseases;Nervous system;Circulatory system;Nervous system;Endocrine system;Signal transduction;Nervous system;Endocrine system;Neurodegenerative diseases;Immune system;Signal transduction;Nervous system;Immune system;Nervous system;Endocrine system;Infectious diseases;Endocrine system;Environmental adaptation;Endocrine system;Substance dependence;Nervous system;Endocrine system;Cellular community - eukaryotes;Infectious diseases;Endocrine system;Digestive system;Nervous system;Endocrine system;Substance dependence | ko05200//Pathways in cancer;ko05170//Human immunodeficiency virus 1 infection;ko04015//Rap1 signaling pathway;ko05163//Human cytomegalovirus infection;ko04024//cAMP signaling pathway;ko05034//Alcoholism;ko04062//Chemokine signaling pathway;ko04360//Axon guidance;ko04022//cGMP - PKG signaling pathway;ko04934//Cushing syndrome;ko04921//Oxytocin signaling pathway;ko05142//Chagas disease (American trypanosomiasis);ko04723//Retrograde endocannabinoid signaling;ko04261//Adrenergic signaling in cardiomyocytes;ko04726//Serotonergic synapse;ko04915//Estrogen signaling pathway;ko04371//Apelin signaling pathway;ko04728//Dopaminergic synapse;ko04926//Relaxin signaling pathway;ko05012//Parkinson disease;ko04611//Platelet activation;ko04071//Sphingolipid signaling pathway;ko04724//Glutamatergic synapse;ko04670//Leukocyte transendothelial migration;ko04725//Cholinergic synapse;ko04935//Growth hormone synthesis, secretion and action;ko05145//Toxoplasmosis;ko04928//Parathyroid hormone synthesis, secretion and action;ko04713//Circadian entrainment;ko04916//Melanogenesis;ko05032//Morphine addiction;ko04727//GABAergic synapse;ko04914//Progesterone-mediated oocyte maturation;ko04540//Gap junction;ko05133//Pertussis;ko04924//Renin secretion;ko04971//Gastric acid secretion;ko04730//Long-term depression;ko04923//Regulation of lipolysis in adipocyte;ko05030//Cocaine addiction | K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630;K04630 | GO:0000139//Golgi membrane;GO:0005737//cytoplasm;GO:0005789//endoplasmic reticulum membrane;GO:0005794//Golgi apparatus;GO:0005813//centrosome;GO:0005815//microtubule organizing center;GO:0005834//heterotrimeric G-protein complex;GO:0005856//cytoskeleton;GO:0005886//plasma membrane;GO:0016020//membrane;GO:0030496//midbody;GO:0042588//zymogen granule;GO:0045121//membrane raft | GO:0000166//nucleotide binding;GO:0001664//G protein-coupled receptor binding;GO:0003924//GTPase activity;GO:0005515//protein binding;GO:0005525//GTP binding;GO:0019001//guanyl nucleotide binding;GO:0019003//GDP binding;GO:0019904//protein domain specific binding;GO:0031683//G-protein beta/gamma-subunit complex binding;GO:0031821//G protein-coupled serotonin receptor binding;GO:0032794//GTPase activating protein binding;GO:0046872//metal ion binding | GO:0006906//vesicle fusion;GO:0007049//cell cycle;GO:0007165//signal transduction;GO:0007186//G protein-coupled receptor signaling pathway;GO:0007188//adenylate cyclase-modulating G protein-coupled receptor signaling pathway;GO:0007193//adenylate cyclase-inhibiting G protein-coupled receptor signaling pathway;GO:0007212//dopamine receptor signaling pathway;GO:0007420//brain development;GO:0016239//positive regulation of macroautophagy;GO:0032930//positive regulation of superoxide anion generation;GO:0033864//positive regulation of NAD(P)H oxidase activity;GO:0046039//GTP metabolic process;GO:0051301//cell division;GO:1904707//positive regulation of vascular smooth muscle cell proliferation;GO:2001234//negative regulation of apoptotic signaling pathway |
| ENSMUSG00000000003 | 174 | 4.63 | 4.28 | 0 | o | Pbsn | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | probasin [Source:MGI Symbol;Acc:MGI:1860484] | - | - | - | - | GO:0005576//extracellular region;GO:0005615//extracellular space | GO:0005549//odorant binding;GO:0036094//small molecule binding | - |
| ENSMUSG00000000028 | 566 | 0.10 | 0.06 | 0 | o | Cdc45 | 0.0193764821720187 | 0.0152666338750562 | 0.0194635923387015 | 0.0137187412995272 | 0.021155851027649 | 0.00967383618294983 | 0.0353468276195559 | 0.0121172116343104 | 0.00764267511898843 | 0.0170212524874784 | 0.00993515357910134 | 0.0100489990213341 | 0.00272135353593629 | 0.300799259029589 | 0.0411296765752967 | 0.0222879461278148 | 0.00922815927479784 | 0 | 0.00851772794717646 | 0 | 0 | 0 | 0 | cell division cycle 45 [Source:MGI Symbol;Acc:MGI:1338073] | Cellular Processes | Cell growth and death | ko04110//Cell cycle | K06628 | GO:0005634//nucleus;GO:0005654//nucleoplasm;GO:0005813//centrosome;GO:0031261//DNA replication preinitiation complex;GO:0036064//ciliary basal body | GO:0003682//chromatin binding;GO:0003688//DNA replication origin binding;GO:0003697//single-stranded DNA binding | GO:0000727//double-strand break repair via break-induced replication;GO:0006260//DNA replication;GO:0006270//DNA replication initiation;GO:0007049//cell cycle;GO:0031938//regulation of chromatin silencing at telomere;GO:1902977//mitotic DNA replication preinitiation complex assembly |
| ENSMUSG00000000037 | 969 | 0.03 | 0.01 | 0 | o | Scml2 | 0 | 6.51822261781368e-04 | 0 | 0.00697291273999948 | 0 | 0.0140913972197575 | 0 | 0 | 0.00804803064690071 | 0 | 0 | 0.00307488135570289 | 0 | 0.00615352427719165 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Scm polycomb group protein like 2 [Source:MGI Symbol;Acc:MGI:1340042] | - | - | - | - | GO:0000785//chromatin;GO:0001741//XY body;GO:0005634//nucleus | GO:0003682//chromatin binding;GO:0005515//protein binding;GO:0042393//histone binding | GO:0006355//regulation of transcription, DNA-templated;GO:0006915//apoptotic process;GO:0034613//cellular protein localization;GO:0036353//histone H2A-K119 monoubiquitination;GO:0045892//negative regulation of transcription, DNA-templated |
| ENSMUSG00000000049 | 345 | 1.36 | 1.36 | 0 | o | Apoh | 0 | 4.21032323750288e-04 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | apolipoprotein H [Source:MGI Symbol;Acc:MGI:88058] | Organismal Systems | Digestive system | ko04979//Cholesterol metabolism | K17305 | GO:0005576//extracellular region;GO:0005615//extracellular space;GO:0005737//cytoplasm;GO:0005886//plasma membrane;GO:0009986//cell surface;GO:0034361//very-low-density lipoprotein particle;GO:0034364//high-density lipoprotein particle;GO:0042627//chylomicron | GO:0005543//phospholipid binding;GO:0008201//heparin binding;GO:0008289//lipid binding;GO:0042802//identical protein binding;GO:0060230//lipoprotein lipase activator activity | GO:0001937//negative regulation of endothelial cell proliferation;GO:0006641//triglyceride metabolic process;GO:0007596//blood coagulation;GO:0007597//blood coagulation, intrinsic pathway;GO:0010596//negative regulation of endothelial cell migration;GO:0010898//positive regulation of triglyceride catabolic process;GO:0016525//negative regulation of angiogenesis;GO:0030193//regulation of blood coagulation;GO:0030195//negative regulation of blood coagulation;GO:0031100//animal organ regeneration;GO:0031639//plasminogen activation;GO:0033033//negative regulation of myeloid cell apoptotic process;GO:0034197//triglyceride transport;GO:0034392//negative regulation of smooth muscle cell apoptotic process;GO:0051006//positive regulation of lipoprotein lipase activity;GO:0051917//regulation of fibrinolysis;GO:0051918//negative regulation of fibrinolysis;GO:0060268//negative regulation of respiratory burst |
| ENSMUSG00000000056 | 462 | 0.95 | 0.00 | 0 | o | Narf | 0.284944114457822 | 0.100256198492436 | 0.417174019831076 | 0.256426051030616 | 0.811540435809003 | 0.172384895563896 | 0.25894314164585 | 0.165251835077514 | 0.121298428902441 | 0.179880655958208 | 0.2443831044735 | 0.341741203818638 | 0.235796862937908 | 0.102469745988219 | 0.303571556771138 | 0.0721231273179004 | 0.11734695114078 | 0.110883016115416 | 0.15290685931261 | 0.169788534704801 | 0.0704304710389903 | 0 | 0.288832138215002 | nuclear prelamin A recognition factor [Source:MGI Symbol;Acc:MGI:1914858] | - | - | - | - | GO:0005634//nucleus;GO:0005638//lamin filament;GO:0005654//nucleoplasm;GO:0005730//nucleolus;GO:0031981//nuclear lumen | GO:0005521//lamin binding | GO:0008150//biological_process |
| ENSMUSG00000000058 | 162 | 26.88 | 0.00 | 1 | i92-114o | Cav2 | 0.0191125853346286 | 0.543861451143354 | 0.0210411032708675 | 0.0270706628456463 | 0.0229246886005526 | 0.483417236448765 | 0.0381513452240534 | 0.0161352035463568 | 0.247722111059511 | 0.115576862659296 | 0.00389472556789967 | 0.0171885711023852 | 0.0455491477311982 | 0.285181335073172 | 0.131693885665311 | 0.542862459763093 | 1.00265489116687 | 0.0737734194453572 | 6.14428780257578 | 0.0589411023791273 | 0.0489533768039319 | 0 | 0.030977782734223 | caveolin 2 [Source:MGI Symbol;Acc:MGI:107571] | Cellular Processes;Human Diseases;Cellular Processes;Human Diseases;Human Diseases | Transport and catabolism;Cancers;Cellular community - eukaryotes;Cardiovascular diseases;Infectious diseases | ko04144//Endocytosis;ko05205//Proteoglycans in cancer;ko04510//Focal adhesion;ko05418//Fluid shear stress and atherosclerosis;ko05100//Bacterial invasion of epithelial cells | K12958;K12958;K12958;K12958;K12958 | GO:0000139//Golgi membrane;GO:0002080//acrosomal membrane;GO:0002095//caveolar macromolecular signaling complex;GO:0005634//nucleus;GO:0005635//nuclear envelope;GO:0005637//nuclear inner membrane;GO:0005737//cytoplasm;GO:0005783//endoplasmic reticulum;GO:0005794//Golgi apparatus;GO:0005811//lipid droplet;GO:0005829//cytosol;GO:0005886//plasma membrane;GO:0005887//integral component of plasma membrane;GO:0005901//caveola;GO:0005925//focal adhesion;GO:0009986//cell surface;GO:0016020//membrane;GO:0016021//integral component of membrane;GO:0030133//transport vesicle;GO:0031234//extrinsic component of cytoplasmic side of plasma membrane;GO:0031410//cytoplasmic vesicle;GO:0032991//protein-containing complex;GO:0042383//sarcolemma;GO:0045121//membrane raft;GO:0045202//synapse;GO:0048471//perinuclear region of cytoplasm | GO:0000149//SNARE binding;GO:0005515//protein binding;GO:0019901//protein kinase binding;GO:0019905//syntaxin binding;GO:0030674//protein binding, bridging;GO:0031435//mitogen-activated protein kinase kinase kinase binding;GO:0031748//D1 dopamine receptor binding;GO:0042803//protein homodimerization activity;GO:0046982//protein heterodimerization activity;GO:0051219//phosphoprotein binding;GO:0060090//molecular adaptor activity;GO:0097110//scaffold protein binding | GO:0001937//negative regulation of endothelial cell proliferation;GO:0001938//positive regulation of endothelial cell proliferation;GO:0006897//endocytosis;GO:0006906//vesicle fusion;GO:0007005//mitochondrion organization;GO:0007029//endoplasmic reticulum organization;GO:0007088//regulation of mitotic nuclear division;GO:0007268//chemical synaptic transmission;GO:0008285//negative regulation of cell proliferation;GO:0008286//insulin receptor signaling pathway;GO:0016050//vesicle organization;GO:0019065//receptor-mediated endocytosis of virus by host cell;GO:0030154//cell differentiation;GO:0030512//negative regulation of transforming growth factor beta receptor signaling pathway;GO:0043410//positive regulation of MAPK cascade;GO:0043547//positive regulation of GTPase activity;GO:0044791//positive regulation by host of viral release from host cell;GO:0044794//positive regulation by host of viral process;GO:0048278//vesicle docking;GO:0048741//skeletal muscle fiber development;GO:0050731//positive regulation of peptidyl-tyrosine phosphorylation;GO:0051480//regulation of cytosolic calcium ion concentration;GO:0060161//positive regulation of dopamine receptor signaling pathway;GO:0070836//caveola assembly;GO:0071711//basement membrane organization;GO:1900182//positive regulation of protein localization to nucleus |
| ENSMUSG00000000078 | 318 | 0.00 | 0.00 | 0 | o | Klf6 | 8.50808810060581 | 5.00887658472365 | 1.97749739845177 | 3.74492837828037 | 0.774843503700867 | 6.36378312108263 | 4.28646363118573 | 3.51824264290686 | 7.67033881322298 | 4.40352161100503 | 1.91999071405671 | 2.37374234977979 | 5.57108628928408 | 3.07686901415529 | 4.70576478730283 | 3.65377308780772 | 7.82194549855929 | 12.4533656636283 | 1.63179549070904 | 2.03184828176217 | 12.2292683371217 | 4.32451172623725 | 1.98599853771731 | Kruppel-like factor 6 [Source:MGI Symbol;Acc:MGI:1346318] | - | - | - | - | GO:0001650//fibrillar center;GO:0005654//nucleoplasm;GO:0005730//nucleolus;GO:0005829//cytosol;GO:0043231//intracellular membrane-bounded organelle | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0001228//DNA-binding transcription activator activity, RNA polymerase II-specific;GO:1990837//sequence-specific double-stranded DNA binding | GO:0045944//positive regulation of transcription by RNA polymerase II |
| ENSMUSG00000000085 | 706 | 0.04 | 0.02 | 0 | o | Scmh1 | 0.0101591392456154 | 0.106830243690062 | 0.24474491014859 | 0.117712231351741 | 0.26163071264081 | 0.171146754987414 | 0.137507408943594 | 0.182819932771205 | 0.390700087506767 | 0.354056014284124 | 0.160617259094597 | 0.108220872008302 | 0.165234480854027 | 0.276057983868408 | 0.44811647419622 | 0.089056482655254 | 0.212281660658815 | 0.070610736207208 | 0.100716892870948 | 0.271263005231552 | 0.580331555528541 | 0.0125464217605139 | 0.227190112686296 | sex comb on midleg homolog 1 [Source:MGI Symbol;Acc:MGI:1352762] | - | - | - | - | GO:0005634//nucleus;GO:0010369//chromocenter | GO:0003682//chromatin binding;GO:0005515//protein binding;GO:0042393//histone binding | GO:0006338//chromatin remodeling;GO:0006355//regulation of transcription, DNA-templated;GO:0007275//multicellular organism development;GO:0007283//spermatogenesis;GO:0009952//anterior/posterior pattern specification;GO:0016458//gene silencing;GO:0045892//negative regulation of transcription, DNA-templated |
| ENSMUSG00000000088 | 146 | 0.01 | 0.01 | 0 | o | Cox5a | 0.810780889964733 | 5.07563336617409 | 2.25713480587825 | 1.61106959411304 | 3.38878089076081 | 2.80328903298244 | 3.07549796529209 | 3.37864136371112 | 1.63043904593888 | 1.75093830382736 | 2.63314913744752 | 1.80152593435851 | 2.51943815023651 | 4.29255105355151 | 2.36310138273561 | 4.21675339941778 | 3.49273590662321 | 1.85359694349239 | 2.91867093665094 | 2.94742615122209 | 2.41482121894226 | 1.1670656787525 | 21.1694126913861 | cytochrome c oxidase subunit 5A [Source:MGI Symbol;Acc:MGI:88474] | Metabolism;Human Diseases;Human Diseases;Organismal Systems;Human Diseases;Human Diseases;Metabolism;Organismal Systems | Global and overview maps;Neurodegenerative diseases;Neurodegenerative diseases;Environmental adaptation;Endocrine and metabolic diseases;Neurodegenerative diseases;Energy metabolism;Circulatory system | ko01100//Metabolic pathways;ko05010//Alzheimer disease;ko05016//Huntington disease;ko04714//Thermogenesis;ko04932//Non-alcoholic fatty liver disease (NAFLD);ko05012//Parkinson disease;ko00190//Oxidative phosphorylation;ko04260//Cardiac muscle contraction | K02264;K02264;K02264;K02264;K02264;K02264;K02264;K02264 | GO:0005739//mitochondrion;GO:0005743//mitochondrial inner membrane;GO:0005751//mitochondrial respiratory chain complex IV;GO:0016020//membrane;GO:0043209//myelin sheath | GO:0004129//cytochrome-c oxidase activity;GO:0005515//protein binding;GO:0046872//metal ion binding | GO:0006119//oxidative phosphorylation;GO:0006123//mitochondrial electron transport, cytochrome c to oxygen;GO:1902600//proton transmembrane transport |
| ENSMUSG00000000093 | 711 | 2.75 | 0.14 | 0 | o | Tbx2 | 0.00215337698333867 | 0.00517807346971249 | 0.00261430433830719 | 0 | 0.00244347927013274 | 0.0021173355949896 | 0.00215436452709544 | 0 | 0.0753867350291138 | 0.00278369978593445 | 0.00558098002009153 | 0 | 0.00629538183379437 | 0 | 0 | 0.110184562669155 | 0 | 0 | 0.594789447740044 | 0 | 0 | 0 | 0.030977782734223 | T-box 2 [Source:MGI Symbol;Acc:MGI:98494] | Environmental Information Processing | Signal transduction | ko04013//MAPK signaling pathway - fly | K10176 | GO:0005634//nucleus;GO:0005667//transcription factor complex | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0001227//DNA-binding transcription repressor activity, RNA polymerase II-specific;GO:0003677//DNA binding;GO:0003700//DNA-binding transcription factor activity;GO:0005515//protein binding;GO:0043565//sequence-specific DNA binding;GO:1990837//sequence-specific double-stranded DNA binding | GO:0000122//negative regulation of transcription by RNA polymerase II;GO:0001708//cell fate specification;GO:0001947//heart looping;GO:0003007//heart morphogenesis;GO:0003148//outflow tract septum morphogenesis;GO:0003151//outflow tract morphogenesis;GO:0003203//endocardial cushion morphogenesis;GO:0003256//regulation of transcription from RNA polymerase II promoter involved in myocardial precursor cell differentiation;GO:0003272//endocardial cushion formation;GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II;GO:0007219//Notch signaling pathway;GO:0007275//multicellular organism development;GO:0007521//muscle cell fate determination;GO:0007569//cell aging;GO:0008016//regulation of heart contraction;GO:0008284//positive regulation of cell proliferation;GO:0035050//embryonic heart tube development;GO:0035909//aorta morphogenesis;GO:0036302//atrioventricular canal development;GO:0042733//embryonic digit morphogenesis;GO:0045892//negative regulation of transcription, DNA-templated;GO:0048596//embryonic camera-type eye morphogenesis;GO:0048738//cardiac muscle tissue development;GO:0051145//smooth muscle cell differentiation;GO:0060021//roof of mouth development;GO:0060045//positive regulation of cardiac muscle cell proliferation;GO:0060465//pharynx development;GO:0060560//developmental growth involved in morphogenesis;GO:0060596//mammary placode formation;GO:0072105//ureteric peristalsis;GO:0090398//cellular senescence;GO:1901208//negative regulation of heart looping;GO:1901211//negative regulation of cardiac chamber formation;GO:1905072//cardiac jelly development;GO:1905222//atrioventricular canal morphogenesis |
| ENSMUSG00000000094 | 552 | 0.00 | 0.00 | 0 | o | Tbx4 | 0 | 0.00251838559882015 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0243352799190833 | 0.0206892970682163 | 0 | 0 | 0 | 0 | 0 | 0.0590710304755183 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | T-box 4 [Source:MGI Symbol;Acc:MGI:102556] | - | - | - | - | GO:0005634//nucleus | GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0003677//DNA binding;GO:0003700//DNA-binding transcription factor activity;GO:0005515//protein binding | GO:0001525//angiogenesis;GO:0001708//cell fate specification;GO:0002009//morphogenesis of an epithelium;GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II;GO:0007275//multicellular organism development;GO:0030324//lung development;GO:0030326//embryonic limb morphogenesis;GO:0035108//limb morphogenesis;GO:0035116//embryonic hindlimb morphogenesis;GO:0048705//skeletal system morphogenesis;GO:1990401//embryonic lung development |
| ENSMUSG00000000120 | 427 | 39.79 | 17.91 | 2 | i13-31o253-275i | Ngfr | 0 | 7.27747462082611e-05 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0175609880081314 | 0.039651999414905 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | nerve growth factor receptor (TNFR superfamily, member 16) [Source:MGI Symbol;Acc:MGI:97323] | Environmental Information Processing;Human Diseases;Environmental Information Processing;Environmental Information Processing;Environmental Information Processing;Environmental Information Processing;Organismal Systems;Cellular Processes | Signal transduction;Cancers;Signaling molecules and interaction;Signal transduction;Signal transduction;Signal transduction;Nervous system;Cell growth and death | ko04151//PI3K-Akt signaling pathway;ko05202//Transcriptional misregulation in cancers;ko04060//Cytokine-cytokine receptor interaction;ko04010//MAPK signaling pathway;ko04014//Ras signaling pathway;ko04015//Rap1 signaling pathway;ko04722//Neurotrophin signaling pathway;ko04215//Apoptosis - multiple species | K02583;K02583;K02583;K02583;K02583;K02583;K02583;K02583 | GO:0005634//nucleus;GO:0005635//nuclear envelope;GO:0005654//nucleoplasm;GO:0005737//cytoplasm;GO:0005739//mitochondrion;GO:0005791//rough endoplasmic reticulum;GO:0005794//Golgi apparatus;GO:0005886//plasma membrane;GO:0005911//cell-cell junction;GO:0009897//external side of plasma membrane;GO:0009986//cell surface;GO:0014069//postsynaptic density;GO:0016020//membrane;GO:0016021//integral component of membrane;GO:0030054//cell junction;GO:0030135//coated vesicle;GO:0030426//growth cone;GO:0032590//dendrite membrane;GO:0032809//neuronal cell body membrane;GO:0042995//cell projection;GO:0043197//dendritic spine;GO:0043204//perikaryon;GO:0045121//membrane raft;GO:0045202//synapse;GO:0045334//clathrin-coated endocytic vesicle | GO:0001540//amyloid-beta binding;GO:0005035//death receptor activity;GO:0005168//neurotrophin TRKA receptor binding;GO:0005515//protein binding;GO:0005516//calmodulin binding;GO:0015026//coreceptor activity;GO:0031267//small GTPase binding;GO:0031625//ubiquitin protein ligase binding;GO:0042802//identical protein binding;GO:0043121//neurotrophin binding;GO:0044877//protein-containing complex binding;GO:0048406//nerve growth factor binding;GO:0070678//preprotein binding | GO:0001678//cellular glucose homeostasis;GO:0006886//intracellular protein transport;GO:0006915//apoptotic process;GO:0006919//activation of cysteine-type endopeptidase activity involved in apoptotic process;GO:0007165//signal transduction;GO:0007266//Rho protein signal transduction;GO:0007275//multicellular organism development;GO:0007399//nervous system development;GO:0007411//axon guidance;GO:0007417//central nervous system development;GO:0007623//circadian rhythm;GO:0009611//response to wounding;GO:0010468//regulation of gene expression;GO:0010941//regulation of cell death;GO:0010976//positive regulation of neuron projection development;GO:0010977//negative regulation of neuron projection development;GO:0016048//detection of temperature stimulus;GO:0016525//negative regulation of angiogenesis;GO:0019233//sensory perception of pain;GO:0021675//nerve development;GO:0030154//cell differentiation;GO:0031069//hair follicle morphogenesis;GO:0031643//positive regulation of myelination;GO:0032224//positive regulation of synaptic transmission, cholinergic;GO:0032922//circadian regulation of gene expression;GO:0034599//cellular response to oxidative stress;GO:0035025//positive regulation of Rho protein signal transduction;GO:0035907//dorsal aorta development;GO:0040037//negative regulation of fibroblast growth factor receptor signaling pathway;GO:0042488//positive regulation of odontogenesis of dentin-containing tooth;GO:0042593//glucose homeostasis;GO:0043065//positive regulation of apoptotic process;GO:0043066//negative regulation of apoptotic process;GO:0043410//positive regulation of MAPK cascade;GO:0043524//negative regulation of neuron apoptotic process;GO:0043588//skin development;GO:0045666//positive regulation of neuron differentiation;GO:0048146//positive regulation of fibroblast proliferation;GO:0048511//rhythmic process;GO:0051402//neuron apoptotic process;GO:0051799//negative regulation of hair follicle development;GO:0051897//positive regulation of protein kinase B signaling;GO:0051902//negative regulation of mitochondrial depolarization;GO:0051968//positive regulation of synaptic transmission, glutamatergic;GO:0061000//negative regulation of dendritic spine development;GO:1900182//positive regulation of protein localization to nucleus;GO:1901216//positive regulation of neuron death;GO:1902895//positive regulation of pri-miRNA transcription by RNA polymerase II;GO:1903588//negative regulation of blood vessel endothelial cell proliferation involved in sprouting angiogenesis;GO:1904646//cellular response to amyloid-beta;GO:2000179//positive regulation of neural precursor cell proliferation;GO:2000377//regulation of reactive oxygen species metabolic process;GO:2000463//positive regulation of excitatory postsynaptic potential;GO:2001235//positive regulation of apoptotic signaling pathway |
| ENSMUSG00000000125 | 355 | 15.32 | 15.26 | 1 | i5-27o | Wnt3 | 0 | 0 | 0 | 0.0086264761315481 | 0 | 0 | 0.00909792367147814 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | wingless-type MMTV integration site family, member 3 [Source:MGI Symbol;Acc:MGI:98955] | Human Diseases;Human Diseases;Human Diseases;Human Diseases;Human Diseases;Human Diseases;Environmental Information Processing;Human Diseases;Environmental Information Processing;Environmental Information Processing;Human Diseases;Human Diseases;Cellular Processes;Organismal Systems;Human Diseases | Cancers;Infectious diseases;Neurodegenerative diseases;Cancers;Cancers;Cancers;Signal transduction;Endocrine and metabolic diseases;Signal transduction;Signal transduction;Cancers;Cancers;Cellular community - eukaryotes;Endocrine system;Cancers | ko05200//Pathways in cancer;ko05165//Human papillomavirus infection;ko05010//Alzheimer disease;ko05205//Proteoglycans in cancer;ko05225//Hepatocellular carcinoma;ko05206//MicroRNAs in cancer;ko04310//Wnt signaling pathway;ko04934//Cushing syndrome;ko04150//mTOR signaling pathway;ko04390//Hippo signaling pathway;ko05226//Gastric cancer;ko05224//Breast cancer;ko04550//Signaling pathways regulating pluripotency of stem cells;ko04916//Melanogenesis;ko05217//Basal cell carcinoma | K00312;K00312;K00312;K00312;K00312;K00312;K00312;K00312;K00312;K00312;K00312;K00312;K00312;K00312;K00312 | GO:0005576//extracellular region;GO:0005615//extracellular space;GO:0005737//cytoplasm;GO:0005788//endoplasmic reticulum lumen;GO:0031012//extracellular matrix | GO:0005102//signaling receptor binding;GO:0005109//frizzled binding;GO:0005125//cytokine activity;GO:0005515//protein binding;GO:0019904//protein domain specific binding;GO:0048018//receptor ligand activity | GO:0000902//cell morphogenesis;GO:0001707//mesoderm formation;GO:0007165//signal transduction;GO:0007267//cell-cell signaling;GO:0007275//multicellular organism development;GO:0007276//gamete generation;GO:0007411//axon guidance;GO:0009887//animal organ morphogenesis;GO:0009948//anterior/posterior axis specification;GO:0009950//dorsal/ventral axis specification;GO:0009952//anterior/posterior pattern specification;GO:0010628//positive regulation of gene expression;GO:0016055//Wnt signaling pathway;GO:0030177//positive regulation of Wnt signaling pathway;GO:0030182//neuron differentiation;GO:0035115//embryonic forelimb morphogenesis;GO:0035116//embryonic hindlimb morphogenesis;GO:0044338//canonical Wnt signaling pathway involved in mesenchymal stem cell differentiation;GO:0044339//canonical Wnt signaling pathway involved in osteoblast differentiation;GO:0045165//cell fate commitment;GO:0048646//anatomical structure formation involved in morphogenesis;GO:0048697//positive regulation of collateral sprouting in absence of injury;GO:0048843//negative regulation of axon extension involved in axon guidance;GO:0050767//regulation of neurogenesis;GO:0060064//Spemann organizer formation at the anterior end of the primitive streak;GO:0060070//canonical Wnt signaling pathway;GO:0060173//limb development;GO:0060174//limb bud formation;GO:0060323//head morphogenesis;GO:0061180//mammary gland epithelium development;GO:0072089//stem cell proliferation;GO:1904954//canonical Wnt signaling pathway involved in midbrain dopaminergic neuron differentiation;GO:1905474//canonical Wnt signaling pathway involved in stem cell proliferation |
| ENSMUSG00000000126 | 365 | 18.30 | 18.03 | 1 | i7-29o | Wnt9a | 0 | 0 | 0 | 0 | 0 | 4.23592725421858e-04 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | wingless-type MMTV integration site family, member 9A [Source:MGI Symbol;Acc:MGI:2446084] | Human Diseases;Human Diseases;Human Diseases;Human Diseases;Human Diseases;Environmental Information Processing;Human Diseases;Environmental Information Processing;Environmental Information Processing;Human Diseases;Human Diseases;Cellular Processes;Organismal Systems;Human Diseases | Cancers;Infectious diseases;Neurodegenerative diseases;Cancers;Cancers;Signal transduction;Endocrine and metabolic diseases;Signal transduction;Signal transduction;Cancers;Cancers;Cellular community - eukaryotes;Endocrine system;Cancers | ko05200//Pathways in cancer;ko05165//Human papillomavirus infection;ko05010//Alzheimer disease;ko05205//Proteoglycans in cancer;ko05225//Hepatocellular carcinoma;ko04310//Wnt signaling pathway;ko04934//Cushing syndrome;ko04150//mTOR signaling pathway;ko04390//Hippo signaling pathway;ko05226//Gastric cancer;ko05224//Breast cancer;ko04550//Signaling pathways regulating pluripotency of stem cells;ko04916//Melanogenesis;ko05217//Basal cell carcinoma | K01064;K01064;K01064;K01064;K01064;K01064;K01064;K01064;K01064;K01064;K01064;K01064;K01064;K01064 | GO:0005576//extracellular region;GO:0005615//extracellular space | GO:0005102//signaling receptor binding;GO:0005109//frizzled binding;GO:0005125//cytokine activity;GO:0005515//protein binding;GO:0048018//receptor ligand activity | GO:0007275//multicellular organism development;GO:0008285//negative regulation of cell proliferation;GO:0016055//Wnt signaling pathway;GO:0030182//neuron differentiation;GO:0032331//negative regulation of chondrocyte differentiation;GO:0035115//embryonic forelimb morphogenesis;GO:0043154//negative regulation of cysteine-type endopeptidase activity involved in apoptotic process;GO:0045165//cell fate commitment;GO:0045597//positive regulation of cell differentiation;GO:0045880//positive regulation of smoothened signaling pathway;GO:0048704//embryonic skeletal system morphogenesis;GO:0048856//anatomical structure development;GO:0060070//canonical Wnt signaling pathway;GO:0060548//negative regulation of cell death;GO:0061037//negative regulation of cartilage development |
| ENSMUSG00000000127 | 823 | 0.15 | 0.00 | 0 | o | Fer | 0.0379900306290234 | 0.141461051124273 | 0.0149045978476251 | 0.0023845265294516 | 0.0498058664368389 | 0.13431630674484 | 0.00759879034581507 | 0.114545026944716 | 0.298132194593045 | 0.00526500545182965 | 0.0182786487123063 | 0 | 0.0115332306459115 | 0.049560522064136 | 0.0991394923690196 | 0.134336285629166 | 0.0787920174627168 | 0.257801398872877 | 0.15502222432743 | 0.02687478500172 | 0.0416659722337961 | 0.193977293170416 | 0 | fer (fms/fps related) protein kinase [Source:MGI Symbol;Acc:MGI:105917] | Cellular Processes | Cellular community - eukaryotes | ko04520//Adherens junction | K08889 | GO:0000785//chromatin;GO:0005634//nucleus;GO:0005737//cytoplasm;GO:0005829//cytosol;GO:0005856//cytoskeleton;GO:0005886//plasma membrane;GO:0005938//cell cortex;GO:0015629//actin cytoskeleton;GO:0015630//microtubule cytoskeleton;GO:0016020//membrane;GO:0030027//lamellipodium;GO:0030054//cell junction;GO:0031234//extrinsic component of cytoplasmic side of plasma membrane;GO:0042995//cell projection | GO:0000166//nucleotide binding;GO:0003779//actin binding;GO:0004672//protein kinase activity;GO:0004713//protein tyrosine kinase activity;GO:0004714//transmembrane receptor protein tyrosine kinase activity;GO:0004715//non-membrane spanning protein tyrosine kinase activity;GO:0005102//signaling receptor binding;GO:0005154//epidermal growth factor receptor binding;GO:0005515//protein binding;GO:0005524//ATP binding;GO:0008092//cytoskeletal protein binding;GO:0008157//protein phosphatase 1 binding;GO:0008289//lipid binding;GO:0016301//kinase activity;GO:0016740//transferase activity;GO:0019901//protein kinase binding;GO:0031267//small GTPase binding;GO:0045295//gamma-catenin binding;GO:0045296//cadherin binding;GO:0050839//cell adhesion molecule binding | GO:0000226//microtubule cytoskeleton organization;GO:0001932//regulation of protein phosphorylation;GO:0006468//protein phosphorylation;GO:0006935//chemotaxis;GO:0007155//cell adhesion;GO:0007165//signal transduction;GO:0007169//transmembrane receptor protein tyrosine kinase signaling pathway;GO:0007260//tyrosine phosphorylation of STAT protein;GO:0008283//cell proliferation;GO:0008284//positive regulation of cell proliferation;GO:0010591//regulation of lamellipodium assembly;GO:0010762//regulation of fibroblast migration;GO:0016310//phosphorylation;GO:0018108//peptidyl-tyrosine phosphorylation;GO:0019221//cytokine-mediated signaling pathway;GO:0030154//cell differentiation;GO:0030335//positive regulation of cell migration;GO:0030838//positive regulation of actin filament polymerization;GO:0031532//actin cytoskeleton reorganization;GO:0032496//response to lipopolysaccharide;GO:0032869//cellular response to insulin stimulus;GO:0033007//negative regulation of mast cell activation involved in immune response;GO:0034446//substrate adhesion-dependent cell spreading;GO:0034614//cellular response to reactive oxygen species;GO:0035426//extracellular matrix-cell signaling;GO:0036006//cellular response to macrophage colony-stimulating factor stimulus;GO:0036119//response to platelet-derived growth factor;GO:0038028//insulin receptor signaling pathway via phosphatidylinositol 3-kinase;GO:0038095//Fc-epsilon receptor signaling pathway;GO:0038109//Kit signaling pathway;GO:0042058//regulation of epidermal growth factor receptor signaling pathway;GO:0043304//regulation of mast cell degranulation;GO:0044331//cell-cell adhesion mediated by cadherin;GO:0045087//innate immune response;GO:0046777//protein autophosphorylation;GO:0048008//platelet-derived growth factor receptor signaling pathway;GO:0050904//diapedesis;GO:0051092//positive regulation of NF-kappaB transcription factor activity;GO:0070102//interleukin-6-mediated signaling pathway |
| ENSMUSG00000000131 | 1125 | 0.45 | 0.03 | 0 | o | Xpo6 | 1.06462955544132 | 0.365855290699946 | 0.613139304275265 | 0.904737462592693 | 0.480837746051826 | 0.517317053630975 | 0.60036192085355 | 0.544139677436669 | 0.4562834073691 | 0.409934437160878 | 0.489298112554128 | 0.617241220622795 | 0.590603940149229 | 0.336752196291509 | 0.578397186606294 | 0.200201262400506 | 0.396762150276673 | 1.11908608358566 | 0.211680492814387 | 0.408531436186456 | 0.16520949692252 | 0.400492096796106 | 0.471894890317997 | exportin 6 [Source:MGI Symbol;Acc:MGI:2429950] | - | - | - | - | GO:0005634//nucleus;GO:0005654//nucleoplasm;GO:0005730//nucleolus;GO:0005737//cytoplasm;GO:0005829//cytosol;GO:0005886//plasma membrane;GO:0032991//protein-containing complex | GO:0005049//nuclear export signal receptor activity;GO:0031267//small GTPase binding | GO:0006611//protein export from nucleus;GO:0006886//intracellular protein transport;GO:0015031//protein transport |
| ENSMUSG00000000134 | 572 | 0.01 | 0.00 | 0 | o | Tfe3 | 0.508448274769801 | 0.443336573765634 | 0.237916917478847 | 0.211528206927359 | 0.126454996072385 | 0.606288726643341 | 0.237082414943877 | 0.119558491621988 | 1.30866330357797 | 0.449316054941173 | 0.135929110120799 | 0.112877517520745 | 1.10945224614517 | 0.384690493572155 | 0.34280198026137 | 0.259390322511219 | 0.52872018459223 | 0.132772449988035 | 0.0534821565509948 | 0.16074489925697 | 0.531181684917022 | 0.499792406262665 | 0.89256479774068 | transcription factor E3 [Source:MGI Symbol;Acc:MGI:98511] | Human Diseases;Human Diseases;Cellular Processes | Cancers;Cancers;Transport and catabolism | ko05202//Transcriptional misregulation in cancers;ko05211//Renal cell carcinoma;ko04137//Mitophagy - animal | K09105;K09105;K09105 | GO:0005634//nucleus;GO:0005654//nucleoplasm;GO:0005667//transcription factor complex;GO:0005737//cytoplasm;GO:0005829//cytosol | GO:0000976//transcription regulatory region sequence-specific DNA binding;GO:0000978//RNA polymerase II proximal promoter sequence-specific DNA binding;GO:0000981//DNA-binding transcription factor activity, RNA polymerase II-specific;GO:0001228//DNA-binding transcription activator activity, RNA polymerase II-specific;GO:0003677//DNA binding;GO:0003700//DNA-binding transcription factor activity;GO:0046982//protein heterodimerization activity;GO:0046983//protein dimerization activity;GO:1990837//sequence-specific double-stranded DNA binding | GO:0002250//adaptive immune response;GO:0002376//immune system process;GO:0006355//regulation of transcription, DNA-templated;GO:0006357//regulation of transcription by RNA polymerase II;GO:0006959//humoral immune response;GO:0045670//regulation of osteoclast differentiation;GO:0045785//positive regulation of cell adhesion;GO:0045893//positive regulation of transcription, DNA-templated;GO:0045944//positive regulation of transcription by RNA polymerase II;GO:0090336//positive regulation of brown fat cell differentiation;GO:0120163//negative regulation of cold-induced thermogenesis |
| ENSMUSG00000000142 | 840 | 0.01 | 0.00 | 0 | o | Axin2 | 0.00197704224402428 | 0.00184461719998063 | 0.00808517977918577 | 0.288340954994737 | 0 | 2.49442520910018e-04 | 0.481652756901986 | 0.0327269703325554 | 0.0421486653001751 | 0.0157661647666008 | 0.00252720308082187 | 0.251772249900929 | 0.00238750380508419 | 0.0632165252296197 | 0.439403634900056 | 0.0353656873266873 | 0 | 0.321777905248474 | 0.0351535242286877 | 0.0155176753894061 | 0 | 0 | 0.257958004436878 | axin 2 [Source:MGI Symbol;Acc:MGI:1270862] | Human Diseases;Human Diseases;Human Diseases;Human Diseases;Environmental Information Processing;Human Diseases;Environmental Information Processing;Human Diseases;Human Diseases;Cellular Processes;Human Diseases;Human Diseases;Human Diseases | Cancers;Infectious diseases;Neurodegenerative diseases;Cancers;Signal transduction;Endocrine and metabolic diseases;Signal transduction;Cancers;Cancers;Cellular community - eukaryotes;Cancers;Cancers;Cancers | ko05200//Pathways in cancer;ko05165//Human papillomavirus infection;ko05010//Alzheimer disease;ko05225//Hepatocellular carcinoma;ko04310//Wnt signaling pathway;ko04934//Cushing syndrome;ko04390//Hippo signaling pathway;ko05226//Gastric cancer;ko05224//Breast cancer;ko04550//Signaling pathways regulating pluripotency of stem cells;ko05210//Colorectal cancer;ko05217//Basal cell carcinoma;ko05213//Endometrial cancer | K04385;K04385;K04385;K04385;K04385;K04385;K04385;K04385;K04385;K04385;K04385;K04385;K04385 | GO:0005634//nucleus;GO:0005737//cytoplasm;GO:0005813//centrosome;GO:0032991//protein-containing complex | GO:0005515//protein binding;GO:0008013//beta-catenin binding;GO:0019899//enzyme binding;GO:0019901//protein kinase binding;GO:0031625//ubiquitin protein ligase binding;GO:0070411//I-SMAD binding | GO:0001756//somitogenesis;GO:0001934//positive regulation of protein phosphorylation;GO:0001957//intramembranous ossification;GO:0003139//secondary heart field specification;GO:0003413//chondrocyte differentiation involved in endochondral bone morphogenesis;GO:0008219//cell death;GO:0008283//cell proliferation;GO:0008285//negative regulation of cell proliferation;GO:0010718//positive regulation of epithelial to mesenchymal transition;GO:0010942//positive regulation of cell death;GO:0016055//Wnt signaling pathway;GO:0030111//regulation of Wnt signaling pathway;GO:0030282//bone mineralization;GO:0032423//regulation of mismatch repair;GO:0034613//cellular protein localization;GO:0042476//odontogenesis;GO:0043570//maintenance of DNA repeat elements;GO:0045668//negative regulation of osteoblast differentiation;GO:0045860//positive regulation of protein kinase activity;GO:0048255//mRNA stabilization;GO:0061181//regulation of chondrocyte development;GO:0070602//regulation of centromeric sister chromatid cohesion;GO:0090090//negative regulation of canonical Wnt signaling pathway;GO:2000054//negative regulation of Wnt signaling pathway involved in dorsal/ventral axis specification |
| ENSMUSG00000000148 | 867 | 0.01 | 0.01 | 0 | o | Brat1 | 0.0805739105086268 | 0.126389713744445 | 0.179595594278385 | 0.174527523440783 | 0.140838195379896 | 0.120667669374653 | 0.129538245154426 | 0.132942508257029 | 0.136755892047864 | 0.0653878026863046 | 0.128657939989856 | 0.128712450246633 | 0.105241919308623 | 0.13441039166667 | 0.151534735719614 | 0.0965438129271537 | 0.0576190528572808 | 0.238892199682265 | 0.276912921273249 | 0.137229084337951 | 0 | 0 | 0.268730517037515 | BRCA1-associated ATM activator 1 [Source:MGI Symbol;Acc:MGI:1891679] | - | - | - | - | GO:0005634//nucleus;GO:0005654//nucleoplasm;GO:0005737//cytoplasm | GO:0005515//protein binding | GO:0001934//positive regulation of protein phosphorylation;GO:0006006//glucose metabolic process;GO:0006915//apoptotic process;GO:0006974//cellular response to DNA damage stimulus;GO:0008283//cell proliferation;GO:0010212//response to ionizing radiation;GO:0016477//cell migration;GO:0030307//positive regulation of cell growth;GO:0051646//mitochondrion localization |
9 细胞周期分析
9.1 细胞周期评估
常规样本中,仅干细胞、祖细胞、癌细胞等具备增殖分化潜力的细胞才具有细胞分裂的能力,即处于细胞周期中。我们通过周期蛋白在细胞中的表达情况对细胞所处的细胞周期进行评分,以此直观体现各个样本中的细胞分裂/增殖活性。
 |
| Fig 9-1-1 不同样本的细胞周期指数评估 |
9.2 细胞周期推断
每一个细胞周期都有特征表达的周期蛋白,通过每个细胞周期的特征周期蛋白[22],我们可以对细胞的各个细胞周期进行评分,通过评分,我们可以推测细胞所处的细胞周期:
- 我们可以推测细胞所处的细胞周期细胞在所有细胞周期中的评分均<0,则认为细胞不处于细胞周期中
- 细胞获得最高分值所对应的细胞周期被认为是细胞所处细胞周期
| Cells | Samples | Clusters | G1 | S | G2 | M | CellCycle.Score | Phase |
|---|---|---|---|---|---|---|---|---|
| NP_AAACCCAAGATACATG | NP | 8 | -0.042145058805713 | -0.00129246661027811 | 0.00269136686734972 | 0.00363821526694116 | 0.00363821526694116 | M |
| NP_AAACCCAAGCACTCAT | NP | 8 | 0.0745961538603549 | -0.0833651836809703 | 0.0537941017095921 | 0.042042621540231 | 0.0745961538603549 | G1 |
| NP_AAACCCAAGCATTTCG | NP | 1 | 0.0713589662507556 | 0.0386888974331032 | -0.0739784289966368 | 0.00122212952453046 | 0.0713589662507556 | G1 |
| NP_AAACCCAAGCCGGAAT | NP | 10 | -0.0926926561442492 | -0.0863266063292219 | -0.0275396242226545 | 0.0253352414952554 | 0.0253352414952554 | M |
| NP_AAACCCAAGCTTAAGA | NP | 0 | -0.115470447729413 | -0.0976334723031796 | 0.0405116055191659 | -0.0354991996854712 | 0.0405116055191659 | G2 |
| NP_AAACCCAAGCTTACGT | NP | 0 | -0.0709996067974205 | -0.0475546317940236 | 0.0673627066501246 | 0.00259065835064229 | 0.0673627066501246 | G2 |
| NP_AAACCCACATCAACCA | NP | 14 | -0.0154831399697472 | -0.0340019759283895 | -0.026268696653803 | -0.0654748336085478 | -0.0154831399697472 | non-cycling |
| NP_AAACCCATCAGATTGC | NP | 19 | -0.00960479283899247 | -0.0420234053142075 | -0.0685928073484325 | -0.080740425497878 | -0.00960479283899247 | non-cycling |
| NP_AAACCCATCATGCCAA | NP | 0 | -0.0413919260518897 | -0.0343417640344653 | 0.0383181318803816 | -0.102623592898823 | 0.0383181318803816 | G2 |
| NP_AAACCCATCCCGTGAG | NP | 4 | -0.133207427349107 | 0.037406489419951 | -0.0252592704991908 | -0.0216379037837316 | 0.037406489419951 | S |
| NP_AAACCCATCCGGACGT | NP | 3 | -0.0922808402020432 | -0.0652756262990237 | -0.084062465101442 | 0.018039892741198 | 0.018039892741198 | M |
| NP_AAACGAAAGCAGAAAG | NP | 0 | -0.0669403797552773 | -0.0576436106200369 | 0.0987431243880099 | -0.0210052686905012 | 0.0987431243880099 | G2 |
| NP_AAACGAAAGTGTTCAC | NP | 11 | 0.0686986994427878 | 0.00200690638651332 | 0.0817484070338133 | -0.0585188407865034 | 0.0817484070338133 | G2 |
| NP_AAACGAACATCATCTT | NP | 2 | 0.088289235536006 | 0.121666862932965 | -0.072399537862626 | 0.00787578153271698 | 0.121666862932965 | S |
| NP_AAACGAACATCCTGTC | NP | 0 | -0.0581795015914253 | -0.0479608346247222 | 0.019768415170054 | -0.0530910197499127 | 0.019768415170054 | G2 |
| NP_AAACGAAGTACAGAAT | NP | 7 | -0.117139047956149 | -0.0878542859671115 | -0.08641453638677 | 0.134720094287725 | 0.134720094287725 | M |
| NP_AAACGAAGTATAGGAT | NP | 3 | 0.0242346266770861 | 0.21533897435891 | -0.0465427164399261 | -0.060245454043965 | 0.21533897435891 | S |
| NP_AAACGAAGTTAATGAG | NP | 0 | -0.0737528068255964 | -0.0553146051191973 | 0.0537150840871653 | -0.0803119845923876 | 0.0537150840871653 | G2 |
| NP_AAACGAATCATTGGTG | NP | 0 | -0.0750028697140771 | -0.0607015910110992 | 0.0639188160678494 | -0.0911734145613552 | 0.0639188160678494 | G2 |
| NP_AAACGAATCGCGCCAA | NP | 1 | -0.0280503472679737 | 0.0249418845991424 | -0.141164555660366 | -0.0167984866421269 | 0.0249418845991424 | S |
 |
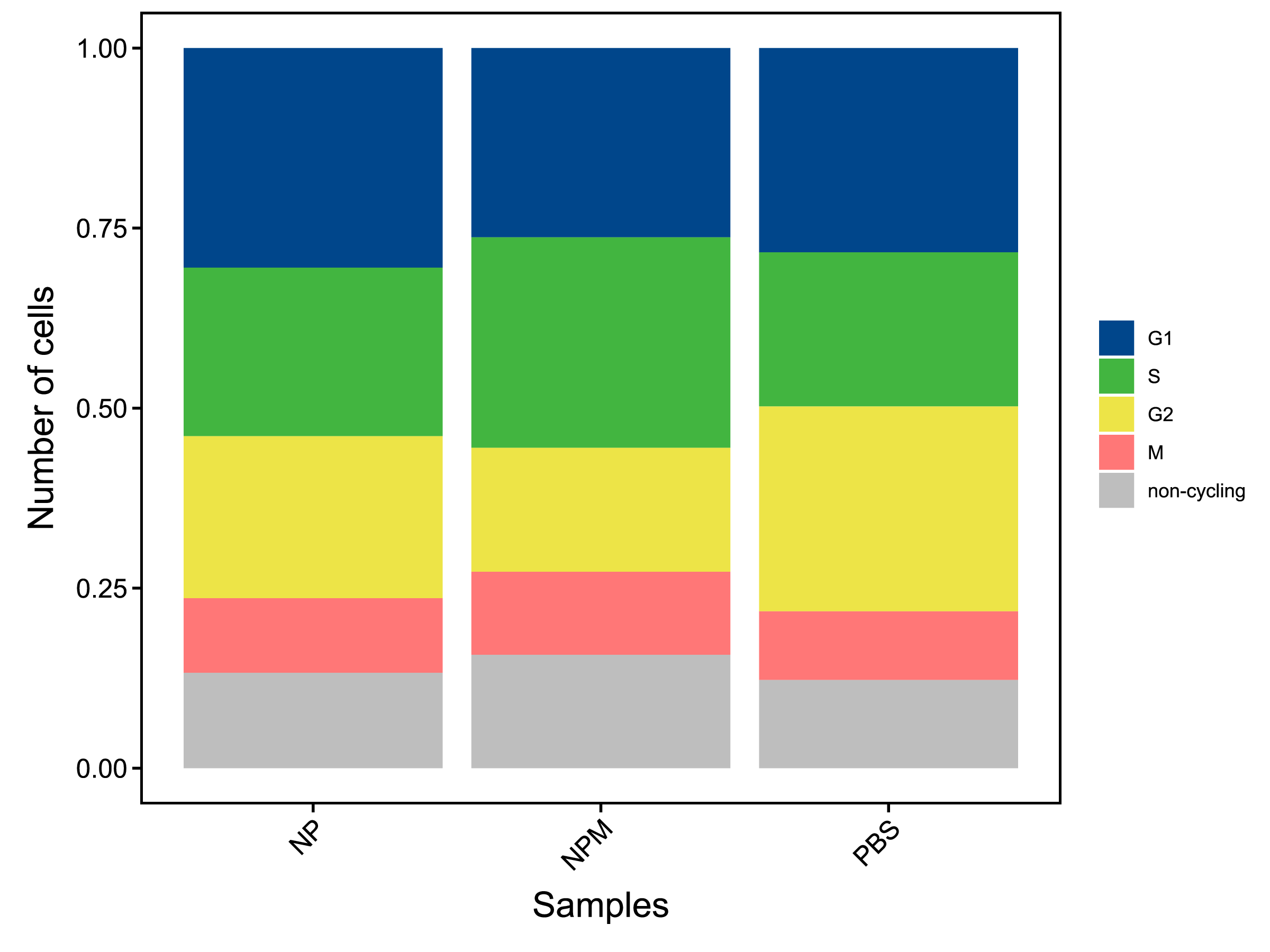 |
|
| Fig 9-2-1 不同样本的不同细胞周期细胞的数量堆叠图 | Fig 9-2-2 不同样本的不同细胞周期细胞的数量比例堆叠图 | |
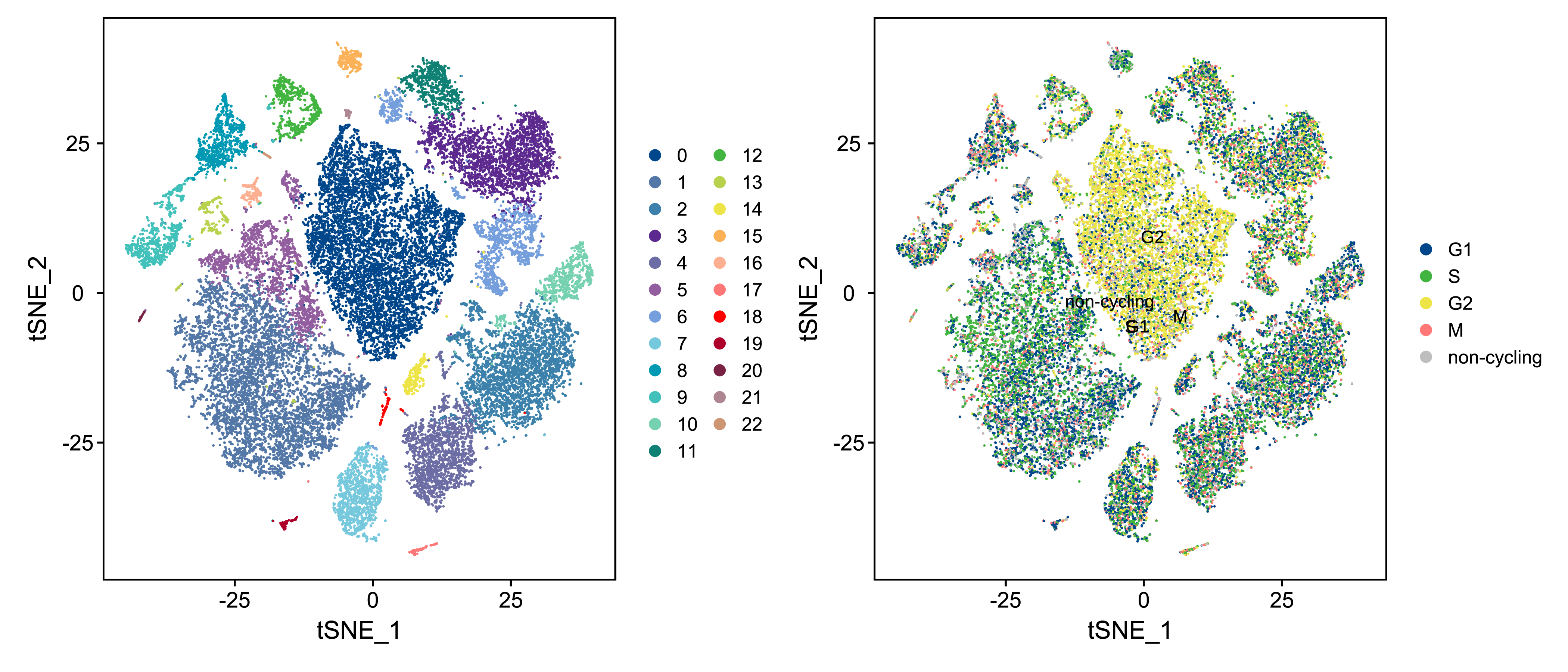 |
| Fig 9-2-3 不同细胞周期细胞的tSNE分布 |
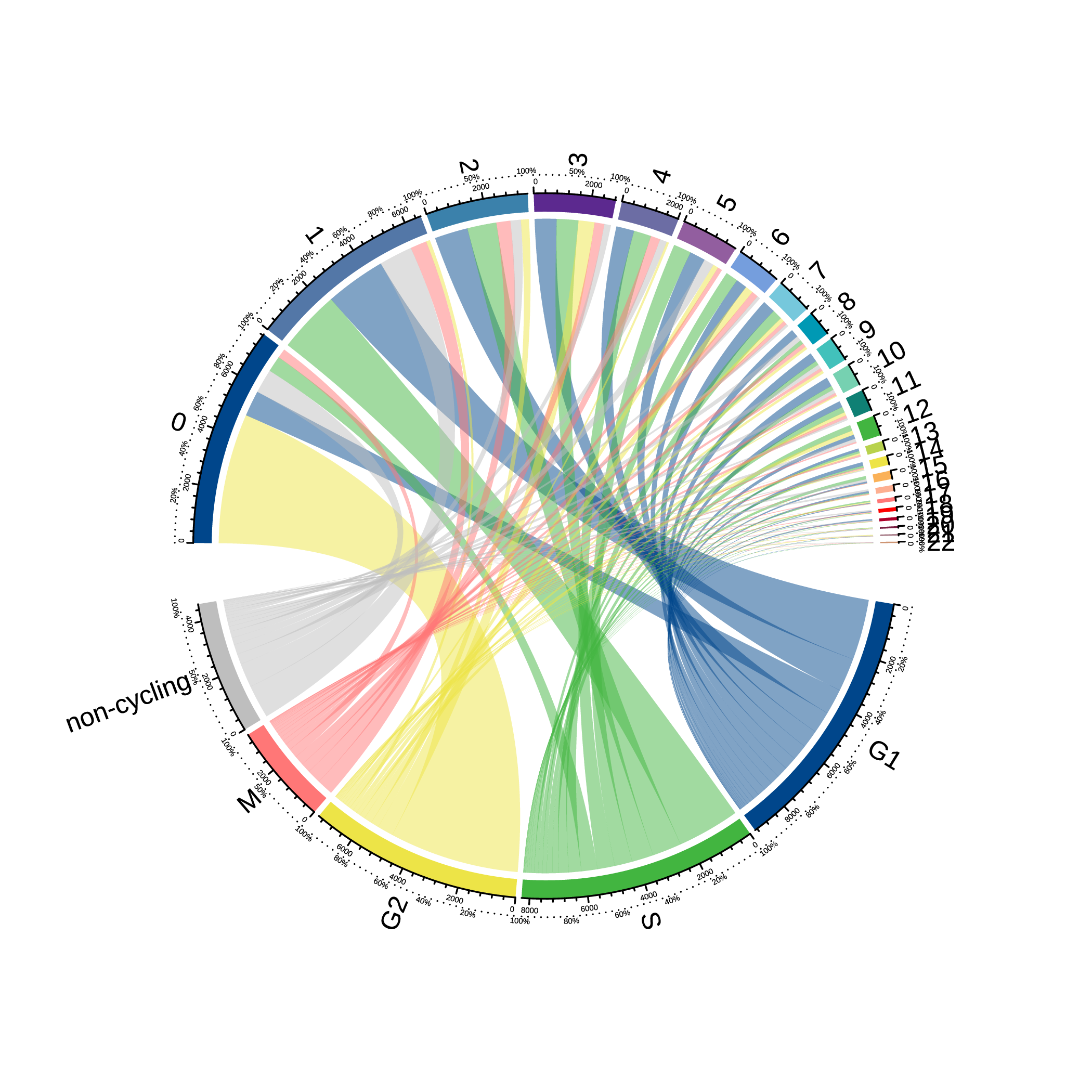 |
| Fig 9-2-4 Seurat分群与细胞周期推断对应circos图 |
9.3 周期蛋白基因分布可视化
细胞周期推断是基于每个细胞周期的特征周期蛋白基因在细胞中的表达量,利用软件预测的结果。那么我们就可以通过观察细胞周期特征基因的表达分布,对预测结果进行初步验证,这个过程即为周期蛋白基因分布可视化。
周期蛋白基因:CellCycle.genes.xls
| G1 | S | G2 | M |
|---|---|---|---|
| Ccne1 | Abcc5 | Arl4a | Ahi1 |
| Ccne2 | Asf1b | Aurkb | Akirin2 |
| Cdc25a | Atad2 | Brd8 | Anln |
| Cdca7 | Brca1 | Bub3 | Anp32e |
| Dtl | Cdkn2aip | Casp3 | Arl6ip1 |
| Ints8 | Cenpq | Ccdc107 | Asxl1 |
| Ivns1abp | Crebzf | Ccna2 | Aurka |
| Mcm2 | Donson | Ccnf | Birc2 |
| Mcm6 | Dscc1 | Cdc25c | Birc5 |
| Nasp | E2f8 | Cdca2 | Bub1 |
| Plcxd1 | Exo1 | Cdca3 | Ccnb2 |
| Skp2 | Ezh2 | Cdca8 | Cdc20 |
| Slbp | Fen1 | Cdk1 | Cdc25b |
| Ung | Hells | Cdkn1b | Cdc27 |
| Zranb2 | Mastl | Cdkn2c | Cenpa |
| - | Pkmyt1 | Cenpl | Cenpe |
| - | Rbbp8 | Ckap2 | Cenpf |
| - | Rfc2 | Ckap2l | Cep55 |
| - | Rrm2 | Dcaf7 | Cit |
| - | Usp1 | Espl1 | Ckap5 |
热图可以同时展示大量基因在每个细胞中的表达量及其在细胞群体中的分布情况。使用热图展示周期蛋白基因在不同细胞周期的表达量,可以看到各时期特征蛋白基因相对集中表达在对应的时期中,是对细胞周期推断结果准确性的验证。
 |
| Fig 9-3-1 周期蛋白基因在不同细胞周期的表达量热图 |
10 个性化分析推荐
10.1 细胞亚群鉴定
细胞亚群鉴定是进行单细胞转录组分析的最基础一步,是赋予细胞数据以生物学意义的关键过程。细胞亚群鉴定主要借助marker基因在各个细胞亚群的表达情况来判断细胞亚群所属细胞类型。按照marker基因的查询方式,我们通常会遇到三种情况:
(1)人、小鼠常见组织的细胞类型注释。如今已经建立了许多数据库用以收集marker基因信息,例如Cell Marker(人、小鼠,http://bio-bigdata.hrbmu.edu.cn/CellMarker/),panglaoDB(人、小鼠,https://panglaodb.se/),MCA(小鼠,http://bis.zju.edu.cn/MCA/)。根据数据库内容,我们可以快速锁定组织类型和细胞类型,并获取相关的marker基因。
(2)人、小鼠罕见组织、稀有细胞类型及其他模式物种的细胞类型注释。这一类细胞通常没有成型的数据库可以快速查询。此时,我们需要从已有的单细胞文章、细胞生物学文章和分子生物学文章找寻相关细胞类型的marker基因。在找寻marker基因时,优先考虑荧光定量PCR(qPCR)和RNA荧光原位杂交(FISH)的结果,因为这些技术直接体现mRNA的表达水平,更容易在scRNA-seq数据中找到表达量分布情况;次级考虑蛋白免疫印迹(western blot)、流式细胞术(FAC)和免疫荧光(IF)的结果,因为蛋白水平和mRNA水平并不是完全同步的,可能出现蛋白高丰度但是mRNA低丰度的情况,使得scRNA-seq不具有相应marker基因的表达分布。
(3)人和模式物种的新细胞类型及非模式物种的细胞类型注释。这一类细胞通常缺乏前人的研究基础,无可直接利用的marker基因。为了完成细胞亚群注释,我们可以使用同源比对的方式将基因比对到具有marker基因信息的近缘物种上,然后使用同源比对得到的marker基因用于注释细胞亚群。当然,细胞类型最终是与细胞功能相关的,我们也可以通过细胞亚群上调基因的功能注释或富集的功能通路来确定细胞功能,并结合生物学背景推测细胞亚群所属的细胞类型。
10.2 拟时分析
细胞分化相关分析一直是研究人员广泛关注的问题,其与胚胎发育、组织修复、疾病发生等多个研究领域紧密相关。单细胞转录组的特征是获得了大量细胞的转录本“快照”,记录了样本中所有细胞的转录本,其中包含了多功能性较强的干细胞、过渡阶段的中间细胞和发育成熟的功能细胞,这为细胞分化相关分析提供了基础。
拟时分析通过分析关键基因的表达模式,将所有细胞按照发育时间的先后排布在拟时间轴上,模拟发育过程中的细胞分化过程。通过对细胞轨迹的分析,我们可以挖掘出细胞分化过程中经历的细胞类型变化、伴随发育过程变化的动态变化基因、祖细胞不同的分化命运等与生命发育息息相关的信息。
10.3 细胞周期分析
胚胎干细胞、肿瘤细胞、生殖细胞、植物根尖、芽尖等细胞除了具备多功能性的分化能力以外,还需具备自我增殖能力。而在增殖过程中,细胞进程必然涉及细胞周期。
细胞周期分析必然在细胞鉴定之后,对具有增殖能力的细胞进行细胞周期分析才具有切实的生物学意义。通过早期的细胞周期研究,我们已知了若干与细胞周期各个时期相关的周期蛋白基因,通过这些基因的表达情况,我们可以进一步推测细胞所处细胞周期。
对细胞周期的分析,既可以深入探索与细胞周期进行有关的新的标记基因,也可以侧面反映样本的细胞更新活性,对样本的表型做出关联解释。
细胞周期分析目前只能分析人和小鼠,其他物种可以同源比对,但存在一定误差。
10.4 WGCNA
单细胞转录组数据的特点是数据庞大,同一个细胞通常带有细胞类型、样本属性、表型特征等多级注释信息,导致单细胞转录组分析时可以进行比较方式多样而繁复。极高的复杂程度需求有效的简化方式。
权重基因共表达网络分析(weighted gene co-expression network analysis, WGCNA)可以将大量的基因简化成少量的具有相同表达模式的模块,并进一步找到与表型相关性最高的基因模块。这一分析极大得简化了数据挖掘过程,有利于从具有复杂样本设计和细胞组成的样本中快速锁定核心基因。
10.5 转录因子分析
转录因子是重要的基因调控元件,在外界刺激中,表达量一般优先发生变化,并进一步调控下游基因的表达完成对刺激的响应。所以,转录因子与靶基因之间具备潜在的共表达关系。
借助这一个基础,我们可以使用软件SCENIC将转录因子和靶基因构建为一个网络单位,通过对网络单位的表达活性的分析来研究不同细胞类型之间的转录调控差异。这种差异同时体现在转录因子的表达情况和转录因子的功能特性(靶基因的表达情况)上,对细胞的表型变化会有更加全面的解释度。
目前转录因子分析只能做人、小鼠和果蝇,其他物种的分析流程待开发。
10.6 细胞通讯分析
多细胞生命体的正常运转离不开多种细胞类型之间的有序合作,生命体的表型变化也不应该是由单一细胞类型的功能决定的。所以,为了获得更具有解释力的分子机制,我们往往需要从细胞间的分子信号交互去解释表型变化。
细胞通讯分析从细胞的配体-受体表达情况去推测细胞类型之间的互作关系。这些互作关系体现了下游细胞的激活、细胞信号转导和靶向细胞的杀伤,在宿主免疫、肿瘤微环境等领域都有广泛的应用前景。
目前细胞通讯分析理论上只能做人的,小鼠基因可以比对到人数据库进行参考分析,其他物种需要提供配受体信息数据库才能进行。
11 目录结构
结果文件夹 ├── 1.Expression 定量结果文件夹 │ ├── barcode_plot 有效细胞鉴定图文件夹 │ │ └── *.barcode_plot.{pdf,png} 有效细胞鉴定图 │ ├── CellRanger_Report Cell Ranger报告文件夹 │ │ └── CellRanger.*.result.html Cell Ranger count结果报告 │ ├── expressions 表达量结果文件夹 │ │ ├── * 各样本结果文件夹 │ │ │ ├── expression.xls 表达量矩阵表 │ │ │ ├── barcodes.tsv 细胞barcode ID表 │ │ │ ├── genes.tsv 基因ID与名称表 │ │ │ └── matrix.mtx 表达量稀疏矩阵 │ │ └── *.expression.demo.xls 表达量矩阵示例表 │ ├── samples.align.stat.xls 各样本比对结果统计表 │ └── samples.sequence.stat.xls 各样本测序数据统计表 ├── 2.Cluster 聚类结果文件夹 │ ├── 1.QC 质控结果文件夹 │ │ ├── AfterFilter.BasicInfo.merge.{pdf,png} 过滤后各个样本细胞基本信息的分布图 │ │ ├── AfterFilter.BasicInfo.nUMI-nGene.{pdf,png} 过滤后各个样本细胞基本信息的分布散点图 │ │ ├── AfterFilter.BasicInfo.nUMI-pMito.{pdf,png} 过滤后各个样本细胞基本信息的分布散点图 │ │ ├── AfterFilter.BasicInfo.PresetMarker.{pdf,png} 过滤后各个样本细胞中预设标记基因的表达量分布 │ │ ├── BasicInfo.merge.{pdf,png} 过滤前各个样本细胞基本信息的分布图 │ │ ├── BasicInfo.nUMI-nGene.{pdf,png} 过滤前各个样本细胞基本信息的分布散点图 │ │ ├── BasicInfo.nUMI-pMito.{pdf,png} 过滤前各个样本细胞基本信息的分布散点图 │ │ ├── BasicInfo.PresetMarker.{pdf,png} 过滤前各个样本细胞中预设标记基因的表达量分布 │ │ └── Filter.stat.xls 过滤前后各个样本中细胞数据量统计表 │ ├── 2.cluster 分群结果文件夹 │ │ ├── AllGene.avg_exp.annot.xls 基因在各个亚群中表达量的均值表 │ │ ├── Cells.cluster.list.xls 细胞与亚群对照表 │ │ ├── tSNE_*.{pdf,png} 各样本单细胞亚群分类tSNE图 │ │ └── tSNE.{pdf,png} 单细胞亚群分类tSNE图 │ ├── 3.cluster_stat 分群结果的统计结果文件夹 │ │ ├── Cluster.stat.inSamples.pct.{pdf,png} 各亚群中各个样本细胞数量百分比堆叠图 │ │ ├── Cluster.stat.inSamples.{pdf,png} 各亚群中各个样本细胞数量堆叠图 │ │ ├── Cluster.stat.bySamples.pct.{pdf,png} 各样本中各亚群细胞数量百分比堆叠图 │ │ ├── Cluster.stat.bySamples.{pdf,png} 各样本中各亚群细胞数量堆叠图 │ │ ├── Cluster.stat.Sample.xls 各样本中各亚群细胞数量统计表 │ │ ├── Cluster.stat.xls 细胞亚群分类结果统计表 │ │ ├── Cluster.cor.heatmap.{pdf,png} 各亚群相关性系数热图 │ │ ├── PresetMarker.Distribution.{pdf,png} 已知标记基因在各个细胞亚群中的表达分布 │ │ ├── PresetMarker.DotPlot.{pdf,png} 已知标记基因在各个细胞亚群中的表达分布气泡图 │ │ ├── PresetMarker.Heatmap.{pdf,png} 已知标记基因在各个亚群的表达量热图 │ │ └── PresetMarker.VlnPlot.{pdf,png} 已知标记基因在各个细胞亚群中的表达分布小提琴图 │ └── 4.CellAnnotation 单细胞亚群鉴定结果文件夹 │ ├── Cell.annotation.stat.xls 各样本在各个细胞类型中细胞数量统计表 │ ├── Cells.annotation.circos.{pdf,png} Seurat分群与singleR细胞鉴定对应circos图 │ ├── Cells.annotation.{pdf,png} 各细胞类型在tSNE图的分布 │ ├── Cluster.correlation.heatmap.{pdf,png} Seurat分群与singleR鉴定细胞类型相关性热图 │ ├── Cluster.sample.singleR.stat.pct.{pdf,png} 各细胞类型中各样本细胞数量百分比堆叠图 │ ├── Cluster.sample.singleR.stat.{pdf,png} 各细胞类型中各样本细胞数量堆叠图 │ ├── Cluster.stat.sample.singleR.xls 各样本在各个细胞类型中细胞数量统计表 │ ├── Sample.cluster.singleR.stat.pct.{pdf,png} 各样本中各细胞类型数量百分比堆叠图 │ └── Sample.cluster.singleR.stat.{pdf,png} 各样本中各细胞类型数量堆叠图 ├── 3.MarkerGene 亚群上调表达基因分析结果文件夹 │ ├── DeGene.list.xls 各亚群差异基因注释表 │ ├── DeGene.stat.{pdf,png} 各亚群上调基因数量统计柱状图 │ ├── DeGene.stat.xls 各亚群上调基因数量统计表 │ ├── Enrichment 上调表达基因富集分析结果文件夹 │ │ ├── GO GO功能富集分析结果文件夹 │ │ ├── KO KO功能富集分析结果文件夹 │ │ ├── DO DO功能富集分析结果文件夹 │ │ └── Reactome Reactome功能富集分析结果文件夹 │ ├── Plots 上调基因表达分布结果文件夹 │ │ ├── Top.DotPlot.{pdf,png} 标记基因表达分布气泡图 │ │ ├── Top.Heatmap.{pdf,png} 标记基因表达热图 │ │ ├── ExpPlot 标记基因表达分布图文件夹 │ │ ├── DensityPlot 标记基因表达分布密度图文件夹 │ │ └── ViolinPlot 标记基因表达分布小提琴图文件夹 │ └── String 蛋白质互作网络分析结果文件夹 │ ├── Top.aln.links.xls 标记基因与String蛋白对应表及析构关系表 │ ├── Top.edge.tsv Cytoscape绘图文件--连接信息文件 │ └── Top.node.tsv Cytoscape绘图文件--节点信息文件 ├── 4.GSVA GSVA分析 │ ├── *.gsva.xls 各细胞富集程度表 │ └── *.heatmap.cluster.{xls,pdf,png} 各个亚群中的富集分数热图 ├── 5.TF 转录因子注释结果文件夹 │ └── TF.annot.xls 转录因子注释表 ├── 6.CellCycle 细胞周期分析 │ ├── CellCycle.annot.xls 各细胞的细胞周期表 │ ├── CellCycle.boxplot.{pdf,png} 不同样本的细胞周期指数评估盒形图 │ ├── CellCycle.DotPlot.{pdf,png} 周期蛋白基因的分布气泡图 │ ├── CellCycle.Heatmap.{pdf,png} 周期蛋白基因在不同细胞周期的表达量热图 │ ├── Phase.stat.bySamples.pct.{pdf,png} 不同样本的不同细胞周期细胞的数量比例堆叠图 │ ├── Phase.stat.bySamples.{pdf,png} 不同样本的不同细胞周期细胞的数量堆叠图 │ ├── CellCycle.Cluster.tSNE.{pdf,png} 不同细胞周期细胞与分群的tSNE分布 │ └── CellCycle.Samples.tSNE.{pdf,png} 不同细胞周期细胞与样本的tSNE分布 ├── 7.RNAVelocity RNA速率分析 │ ├── velocity.trajectory.tSNE.{pdf,png} RNA速率轨迹图 │ └── velocity.tSNE.{pdf,png} RNA速率分布图 ├── index.html 单细胞分析结果网页版报告 ├── scRNA-seq_method.pdf 单细胞分析方法说明(英文版) └── src 网页版报告系统文件文件夹
12 参考文献
- [1] cellranger : http://support.10xgenomics.com/single-cell/software/overview/welcome
- [2] Butler A, Hoffman P, Smibert P, et al. Integrating single-cell transcriptomic data across different conditions, technologies, and species. Nat Biotechnol. 2018;36(5):411-420.
- [3] McGinnis CS, Murrow LM, Gartner ZJ. DoubletFinder: Doublet Detection in Single-Cell RNA Sequencing Data Using Artificial Nearest Neighbors. Cell Syst. 2019 Apr 24;8(4):329-337.e4. doi: 10.1016/j.cels.2019.03.003.
- [4] Korsunsky I, Millard N, Fan J, Slowikowski K, Zhang F, Wei K, Baglaenko Y, Brenner M, Loh PR, Raychaudhuri S. Fast, sensitive and accurate integration of single-cell data with Harmony. Nat Methods. 2019 Dec;16(12):1289-1296.
- [5] van der Maaten Laurens and Hinton Geoffrey. Visualizing data using t-SNE. Journal of Machine Learning Research. 2008;9(November):2579–2605.
- [6] Aran D, Looney AP, Liu L, et al. Reference-based analysis of lung single-cell sequencing reveals a transitional profibrotic macrophage. Nat Immunol. 2019;20(2):163-172.
- [7] Ashburner M, Ball CA, Blake JA, et al. Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat Genetics, 2000;25(1):25-29.
- [8] Kanehisa M, Goto S. KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res, 2000;28(1):27-30.
- [9] Fabregat A, Jupe S, Matthews L, et al. The Reactome Pathway Knowledgebase. Nucleic Acids Res. 2018;46(D1):D649-D655. doi:10.1093/nar/gkx1132
- [10] Schriml LM, Mitraka E, Munro J, et al. Human Disease Ontology 2018 update: classification, content and workflow expansion. Nucleic Acids Res. 2019;47(D1):D955-D962.
- [11] Franceschini A, Szklarczyk D, Frankild S, et al. STRING v9.1: protein-protein interaction networks, with increased coverage and integration. Nucleic Acids Res. 2013;41(Database issue):D808-D815.
- [12] Hänzelmann S, Castelo R, Guinney J. GSVA: gene set variation analysis for microarray and RNA-seq data. BMC Bioinformatics. 2013;14:7.
- [13] Liberzon A, Birger C, Thorvaldsdóttir H, Ghandi M, Mesirov JP, Tamayo P. The Molecular Signatures Database (MSigDB) hallmark gene set collection. Cell Syst. 2015;1(6):417-425.
- [14] Weijun Liu and Xiaowei Wang. Prediction of functional microRNA targets by integrative modeling of microRNA binding and target expression data. Genome Biology. 2019; 20(1):18.
- [15] Yuhao Chen and Xiaowei Wang. miRDB: an online database for prediction of functional microRNA targets. Nucleic Acids Research. 2020;48(D1):D127-D131.
- [16] Griffiths-Jones S, Grocock RJ, van Dongen S, Bateman A, Enright AJ. miRBase: microRNA sequences, targets and gene nomenclature. Nucleic Acids Res. 2006;34(Database issue):D140-D144.
- [17] Yevshin I, Sharipov R, Kolmykov S, Kondrakhin Y, Kolpakov F. GTRD: a database on gene transcription regulation-2019 update. Nucleic Acids Res. 2019;47(D1):D100-D105.
- [18] Xie X, Lu J, Kulbokas EJ, et al. Systematic discovery of regulatory motifs in human promoters and 3' UTRs by comparison of several mammals. Nature. 2005;434(7031):338-345.
- [19] Subramanian A, Tamayo P, Mootha VK, et al. Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proc Natl Acad Sci U S A. 2005;102(43):15545-15550.
- [20] Segal E, Friedman N, Koller D, Regev A. A module map showing conditional activity of expression modules in cancer. Nat Genet. 2004;36(10):1090-1098.
- [21] Godec J, Tan Y, Liberzon A, et al. Compendium of Immune Signatures Identifies Conserved and Species-Specific Biology in Response to Inflammation. Immunity. 2016;44(1):194-206.
- [22] Macosko EZ, Basu A, Satija R, et al. Highly Parallel Genome-wide Expression Profiling of Individual Cells Using Nanoliter Droplets. Cell. 2015;161(5):1202-1214.
13 附录
13.1 分析方法英文文档
scRNA-seq分析方法文档(英文):scRNA-seq_method.pdf
13.2 结果文件查看
*.xls,*.txt :结果数据表格文件,文件以制表符(Tab)分隔。unix/Linux/Mac用户使用 less 或 more 命令查看;windows用户使用高级文本编辑器Notepad++ 等查看,也可以用Microsoft Excel打开。
*.png:结果图像文件,位图,无损压缩。
*.pdf:结果图像文件,矢量图,可以放大和缩小而不失真,方便用户查看和编辑处理,可使用Adobe Illustrator进行图片编辑,用于文章发表等。
13.3 文章引用与致谢
如果您的研究课题使用了基迪奥的测序和分析服务,我们期望您在论文发表时,在Method部分或Acknowledgements部分引用或提及基迪奥公司。以下语句可供参考:
- Method部分:The cDNA/DNA/Small RNA libraries were sequenced on the Illumina sequencing platform by Genedenovo Biotechnology Co., Ltd (Guangzhou, China).
- Acknowledgements部分:We are grateful to/thank Guangzhou Genedenovo Biotechnology Co., Ltd for assisting in sequencing and/or bioinformatics analysis.
